脳波や筋電などの生体情報、プラントなどの製造プロセス、ビルやロボットの状態の計測で得られる情報、などは実世界から得られる時系列データの典型的なものであり、近年、様々な IoT
センサの開発と普及により、その利活用へのニーズが高まっている。
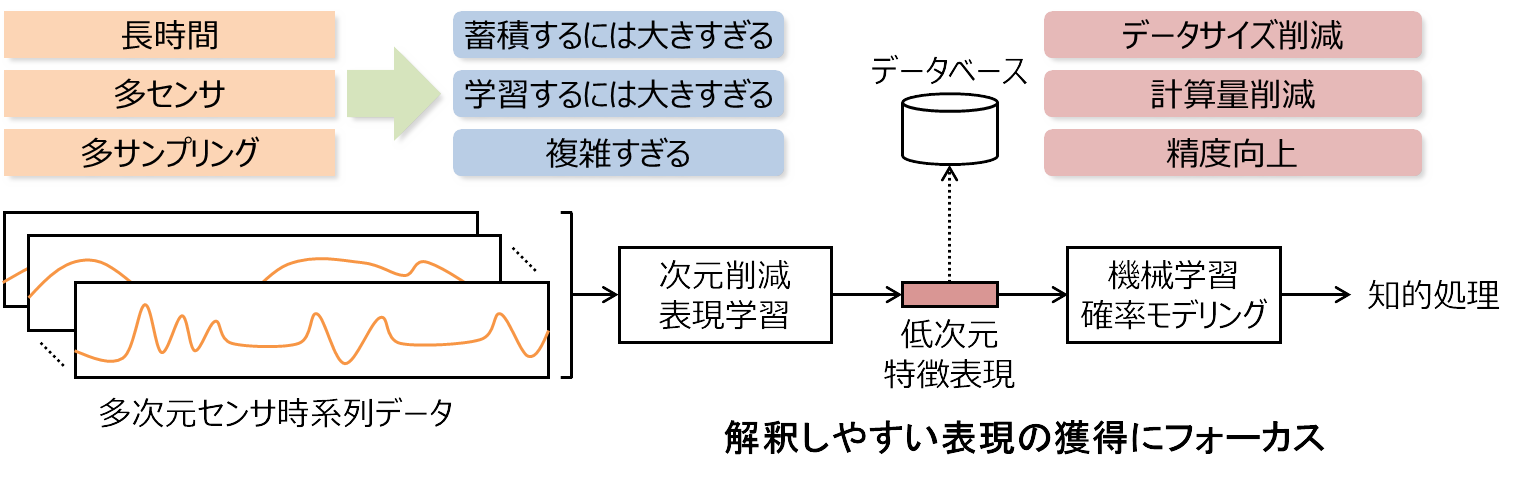
そうした時系列データの圧縮・処理手法として、データを少数の辞書基底に分解するスパース辞書学習(スパースコーディング)が研究されているが、そこで得られる基底は、局所性が小さく、解釈が困難なものも多かった。
そこで、時間スキップ操作に基づくスキップ表現を用いた新たな時系列分解手法(DLTSkip)を開発し、Python
のプログラムとしてモジュール化した。
従来の分解手法に対して、より解釈性の高い時系列分解が得られる可能性がある。また、時系列データの読み込みや表示などの汎用的なプログラムや、分解、圧縮した表現を用いた時系列の識別をするプログラムもあわせて公開している。
Python プログラム公開サイト
https://github.com/aistairc/DLTSkip
手法の詳細に関する論文
Genta Yoshimura, Atsunori Kanemura, Hideki Asoh,
"Reconstructable and Interpretable Representations for Time Series with Time-Skip Sparse Dictionary
Learning", Proceedings of the on Thematic Workshops of ACM Multimedia 2017, doi: 10.1145/3126686.3126724
センサ時系列などの実世界における時系列信号の分解圧縮とそれを用いた、計算量の少ない分類や識別に幅広く応用可能。
| 研究開発プロジェクト | NEDO 次世代人工知能・ロボット中核技術開発の成果 |
| 研究機関 | 国立研究開発法人 産業技術総合研究所 |
| 主要研究者 | 吉村 玄太 |