近年、 IoT
センサの開発と普及によって、様々な分野で、大規模な時系列データを安価に収集することが可能になり、その利活用へのニーズが高まっている。
そうした実世界時系列データは、自然言語テキストなどと同様に、埋め込み構造などの複雑な構造を持つことが多く、そうした構造を明示的知識として利用することで、少量のデータからでも効率の良い学習が可能になる可能性もある。しかし、現在の時系列信号処理の手法では、複雑な構造を適切にモデル化することが難しい。
この問題に対処するために、複雑な確率モデリングを容易に記述し、それを用いた学習や推論を簡便に実行するための確率プログラミング言語の研究開発が盛んになっている。
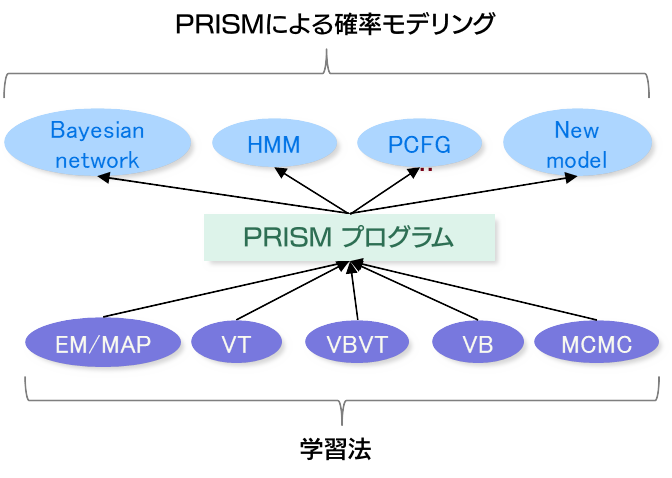
PRISM(Programming
in Statistical Modeling) は、そうしたプログラミング言語の中でも最も初期から継続的に開発が続けられているものの一つであり、論理プログラミングと確率モデリングを融合した言語で、Prolog
like
なシンタックスによる一階述語を使ったルールを使って、複雑な確率モデルを容易に記述できるという特徴を持つ。一階述語命題の確率計算は、分布意味論という理論基盤に立脚しており、統一的な形で、様々な推論や学習のアルゴリズムが、モデル記述と分離した形で実装されている。
PRISM 公開サイト
https://rjida.meijo-u.ac.jp/prism/
各種のセンサデータや、医療データなど複雑な構造が内在している時系列情報の処理など、実世界の情報への確率モデリングの適用に幅広く応用可能である。
| 研究開発プロジェクト | NEDO 次世代人工知能・ロボット中核技術開発の成果 |
| 研究機関 | 国立研究開発法人 産業技術総合研究所 |
| 主要研究者 | 佐藤 泰介 |