動画データセット+動作認識、説明生成(情報抽出)
研究のポイント
人工知能が我々の生活の中に入って育児や介護などを支援できるようになるためには、日常生活の様々な出来事を深く理解している必要がある。本研究ではカメラなどで視覚的に観測された日常シーンにおける人の行動を認識し言語へと変換する技術を開発する。「誰が(誰と)何をしている」など動作主、動作内容、動作対象などをきめ細かく認識する技術を開発する。さらに、映像と言語を統合した長期記憶機構を開発し、過去の出来事について数日まで遡って質問に答えることができるような質問応答機構を実現することを目指す。
【キーワード】動作認識, 深層学習, 動画のキャプション生成, 質問応答
モジュールの概要
- STAIR Actions: 世界最大級の人の動作動画データセットの構築と公開
- STAIR Actions Captions: 世界最大の動作動画キャプションデータセットの構築
- 3DCNN 等の深層ニューラルネットに基づく動作認識モデルとキャプション生成モデルの構築
- STAIR Actions データセットの構築
-
- 100種類の日常動作 x 1000本(合計10万本)の動画データセット
- 世界最大級
- 参考:
- Kinetics 400種 x 750本
- ActivityNet 203種 x 137本
- 公開中 http://actions.stair.center/


- データを用いて認識モデルを構築
- 産総研で開発した動作認識に適する3D-CNN 深層学習モデル(*)を用いて世界トップレベルの認識精度 79.5% を達成
- * https://github.com/kenshohara/3D-ResNets-PyTorch
- STAIR Video Captionsデータセットの構築
- 8万本の動画それぞれに5文の日本語説明文(キャプション)がつけられた40万の動画-説明文ペアのデータセット
- キャプションは「誰が」「どこで」「なにをしている」に分割されている

- 世界最大、日本語では初 参考:MSR-VTT 23万動画-説明文ペア(英語では世界最大)
- 公開中 https://sa-captions.stair.center/
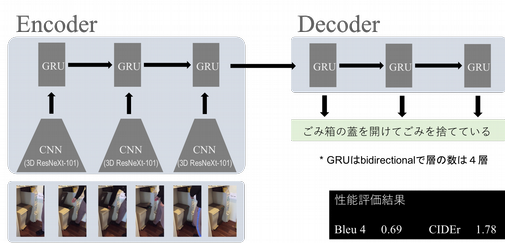
- データを用いて説明文生成モデルを構築
- 説明文生成に適する深層 Encoder-decoderモデルを用いて世界トップレベルの説明文生成性能(Bleu4=0.69, CIDEr=1.78)を達成
- 生成例
ハイライト
100種類の日常動作の認識
動画の内容を説明する文章の生成

想定されるアプリケーション
- 生活を支援する人工知能
- 人の日常動作を認識・理解して支援する人工知能
- 介護・看護・育児などへの応用
