Research Topics
Graph Learning Model Innovations
Over the years, our research has focused on advancing graph learning models through a series of innovations that address both theoretical and practical challenges.
One of our key contributions is in the theoretical analysis of graph embeddings. In the paper "A General View for Network Embedding as Matrix Factorization" (WSDM'19), we provided a unifying framework that connects various network embedding methods through the lens of matrix factorization, offering a new perspective on how these embeddings capture the structural properties of graphs.
Building on this foundation, we explored deep learning applications in community detection with the paper "Learning Community Structure with Variational Autoencoder" (ICDM'18). This work introduced a novel approach using variational autoencoders to identify hidden community structures within networks, demonstrating the power of deep generative models in graph analysis.
In the realm of heterogeneous graphs, our research led to the development of a method for efficient information aggregation, as detailed in "Heterogeneous Graph Embedding with Single-Level Aggregation and Infomax Encoding" (Machine Learning, 2022). This method effectively handles the complexity of graphs with diverse node and edge types, improving performance in tasks such as node classification.
Addressing the challenges in multi-label graphs, the paper "Anonymity Can Help Minority: A Novel Synthetic Data Over-Sampling Strategy on Multi-Label Graphs" (ECML-PKDD'2022) introduced a strategy to handle label imbalances, particularly in complex multi-label environments, thus enhancing the learning process in real-world datasets.
In the study of temporal graphs, our research, "Towards Temporal Knowledge Graph Embeddings with Arbitrary Time Precision," explores how temporal dynamics can be integrated into knowledge graph embeddings, enabling more accurate modeling of time-evolving relationships in dynamic environments. The work on knowledge graphs, highlighted in "What Wikipedia Misses about Yuriko Nakamura? Predicting Missing Biography Content by Learning Latent Life Patterns" (ECAI'23), demonstrates the application of graph learning in predicting and filling missing information in structured data, enriching knowledge bases with latent life patterns.
Recognizing the challenges posed by noisy environments, we contributed to the development of the DEGNN framework in "DEGNN: Dual Experts Graph Neural Network Handling Both Edge and Node Feature Noise" (PAKDD'24). This framework is designed to enhance the robustness of graph neural networks, ensuring their reliability even when data quality is compromised.
Finally, our work on node ranking and feature selection, as seen in "Graph Neural Networks for Fast Node Ranking Approximation" (ACM Transactions on Knowledge Discovery from Data, 2021) and "Feature Selection: Key to Enhance Node Classification with Graph Neural Networks" (CAAI Transactions on Intelligence Technology, 2023), underscores the importance of optimizing graph neural models for more accurate and efficient processing of large-scale graph data.
Together, these works contribute to a deeper understanding and more effective application of graph learning techniques, addressing both theoretical challenges and practical demands in the analysis of complex graph structures.
Applications of Graph Technology
Building on the theoretical advancements in graph learning, our research has extended into various real-world applications, demonstrating the versatility and impact of graph-based approaches across multiple domains.
In recommender systems, our work has made significant strides, particularly in adapting recommendations over time and improving filtering processes. This is exemplified in the papers "Leaping Through Time with Gradient-based Adaptation for Recommendation" (AAAI'22) and "How Powerful is Graph Filtering for Recommendation" (KDD'24), which showcase innovative methods for enhancing personalization and accuracy in recommendation systems.
In the area of citation recommendation, the paper "Enhancing Citation Recommendation Using Citation Network Embedding" (Scientometrics, 2022) demonstrates how embedding techniques can significantly improve the relevance and precision of citation suggestions in academic research, thereby aiding researchers in discovering pertinent literature.
Our research has also addressed challenges in text classification, especially in cross-lingual contexts. The study "Cross-lingual Transfer for Text Classification with Dictionary-based Heterogeneous Graph" (Findings of EMNLP'21) provides a framework for effectively transferring knowledge across languages using heterogeneous graph structures, which is particularly valuable in multilingual text classification tasks.
In the field of healthcare, our contributions include the development of methods for diagnosing brain disorders using graph-based approaches. The paper "Population Graph-Based Multi-Model Ensemble Method for Diagnosing" (Sensors, 2020) demonstrates how multi-model ensemble techniques can improve diagnostic accuracy by leveraging population graph data.
Addressing emergency demand prediction, our work has led to the development of models that forecast demand for emergency medical services. This is seen in "Predicting Emergency Medical Service Demand with Bipartite Graph Convolutional Networks" (IEEE Access, 2021) and "Forecasting Ambulance Demand with Profiled Human Mobility via Heterogeneous Multi-Graph Convolution Network" (ICDE'21). These studies illustrate the effectiveness of graph-based models in managing and predicting emergency service demands, ultimately contributing to more efficient resource allocation.
In the domain of real-time predictions, the paper "Predicting Potential Real-Time Donations in YouTube Live Streaming Services via Continuous-Time Dynamic Graphs" (Machine Learning, 2023) explores the use of dynamic graphs to predict user behavior and optimize donation predictions during live streaming events, highlighting the application of graph learning in online platforms.
Collectively, these applications demonstrate the practical utility of graph technology in solving real-world problems, showcasing its potential to drive innovation and improve outcomes across a variety of fields.
Domain-independent generalized entity matching
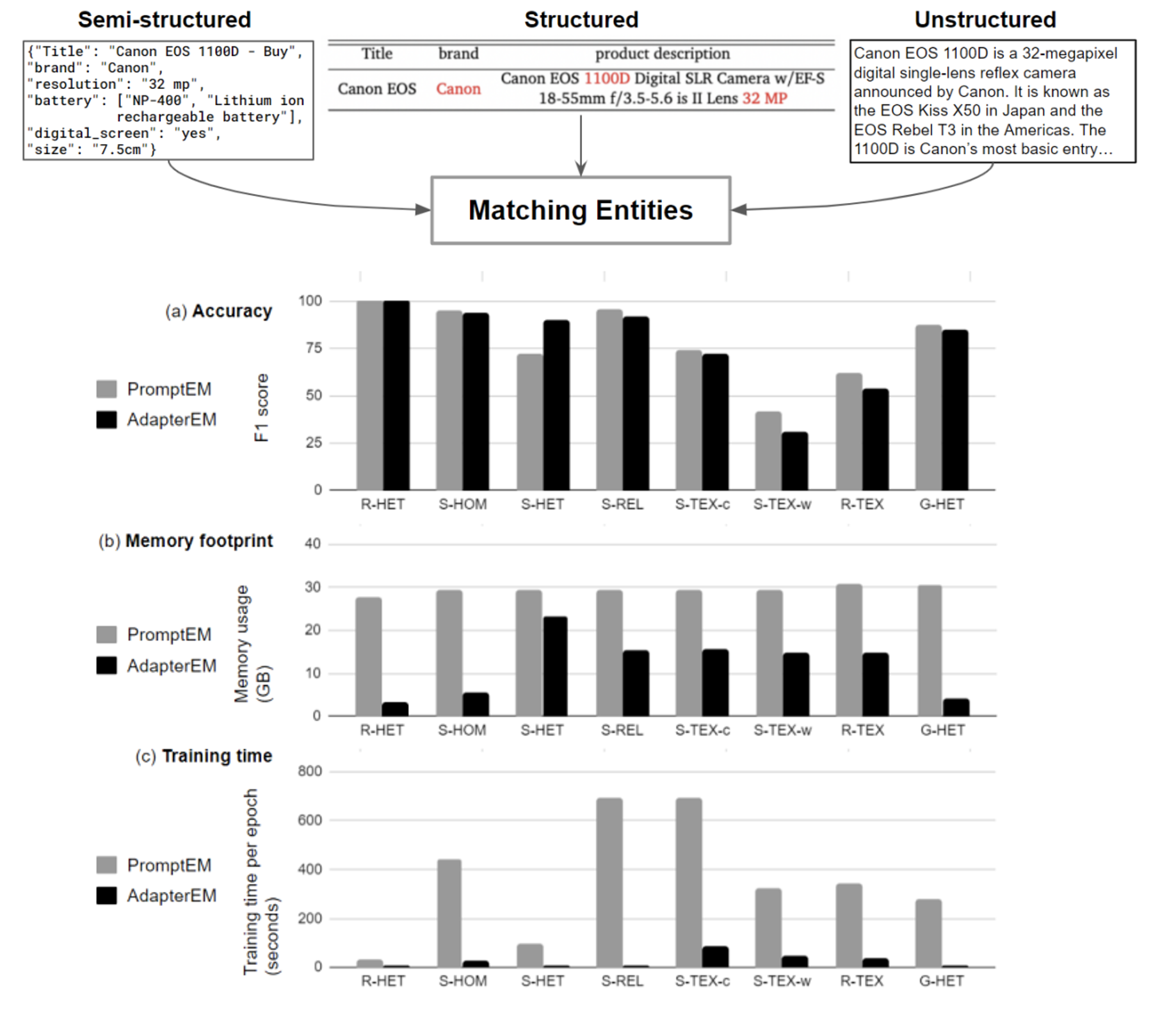
Generalized Entity Matching (GEM) is a variant of entity matching that identifies whether entity descriptions from diverse data sources with heterogeneous data formats refer to the same real-world entity. State-of-the-art single-task fine-tuning approaches have shown limitations in handling scenarios with entity distribution shifts, particularly in low-resource settings, and can also require significant amounts of computationally expensive fine-tuning when applied to the GEM problem.
We have developed a parameter efficient paradigm for fine-tuning pre-trained language models (PrLMs) based on adapters, small neural networks encapsulated between layers of a PrLM, by optimizing only the adapter and classifier weights while the PrLMs parameters are frozen. Adapter-based methods have been successfully applied to multilingual speech problems achieving promising results, however, the effectiveness of these methods when applied to GEM is not yet well understood, particularly for generalized GEM with heterogeneous data. We explore using adapters to capture token-level language representations and demonstrate their benefits for transfer learning on current GEM benchmarks. Applying this has shown to be able to achieve comparable F1 scores with current techniques while substantially reducing memory footprint and training time.
Common sense temporal action knowledge
Many information processing systems require commonsense knowledge which is obvious to humans but difficult to infer or deduce computationally.
One such kind of knowledge is common sense temporal knowledge about actions:
Applicable, for example, in planning in robotics applications. e.g:
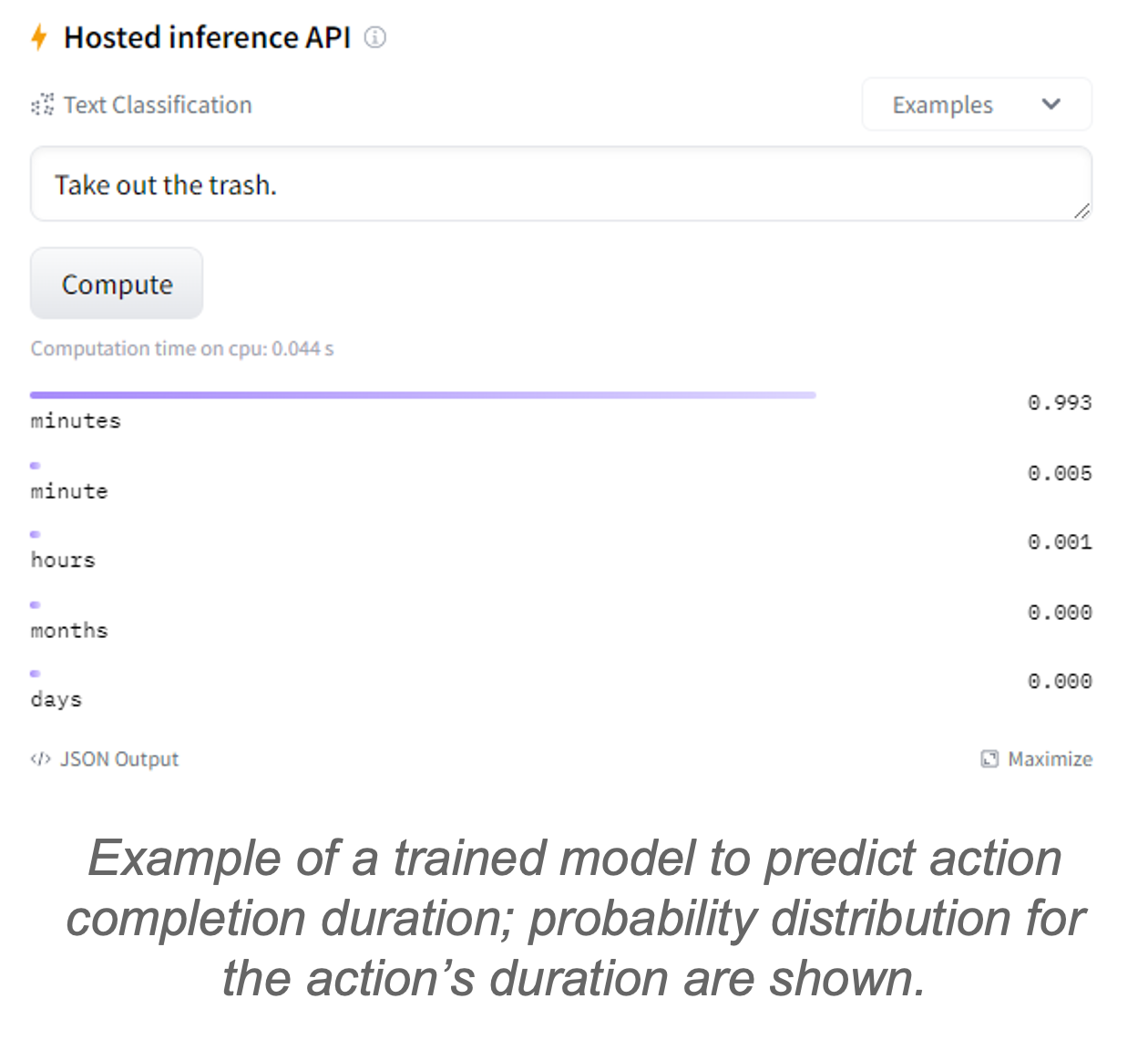
Action: "Take out the trash":
- [Completion duration: minutes] - vital for planning sequences of actions.
- [Effect duration: days] - vital for scheduling future plans, e.g. repeat the task.
We created a dataset of action sequences and their common sense temporal properties using crowdsourcing. We then applied state-of-the-art machine learning techniques to train machine learning models to predict temporal common sense information from any action related sentence.
CoTAK Dataset: Commonsense Temporal Action Knowledge: https://github.com/nsjl/aakg-data
Distributed and Scalable Low-latency Spatial Data Processing
[CIKM 2020], [IEEE Access 2022], [ACM SIGSPATIAL 2022]
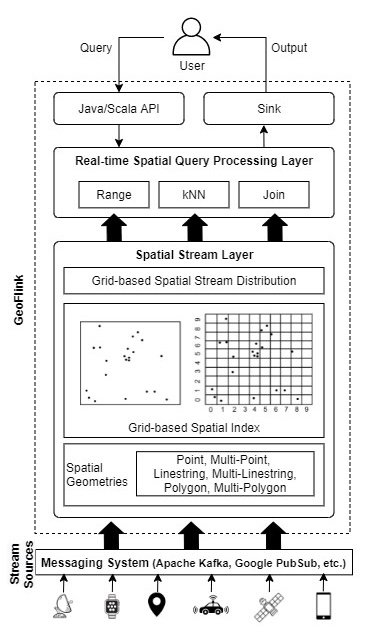
With the increase in the use of GPS-enabled devices, spatial data is omnipresent. Many applications require real-time processing of spatial data, for instance, to provide route guidance in disaster evacuation, for patients tracking to prevent the spread of serious diseases, to support smooth voice and data services to mobile subscribers in all areas, for road traffic monitoring and management, etc. Such applications entail real-time processing of millions of tuples per second. Existing spatial data processing frameworks, for instance, PostGIS and QGIS are not scalable to handle such huge data and throughput requirements, while scalable platforms like Apache Spark Streaming, Apache Flink, Apache Samza, etc. do not natively support spatial data processing, i.e., they lack spatial data objects, indexes, and queries support, resulting in increased spatial querying cost. Besides, there exist a few solutions to handle large scale spatial data, for instance Hadoop GIS, Spatial Hadoop, GeoSpark, etc. However, they cannot handle real-time spatial streams. To this end, we propose GeoFlink, which extends Apache Flink to support spatial objects, indexes and continuous queries over spatial data streams.
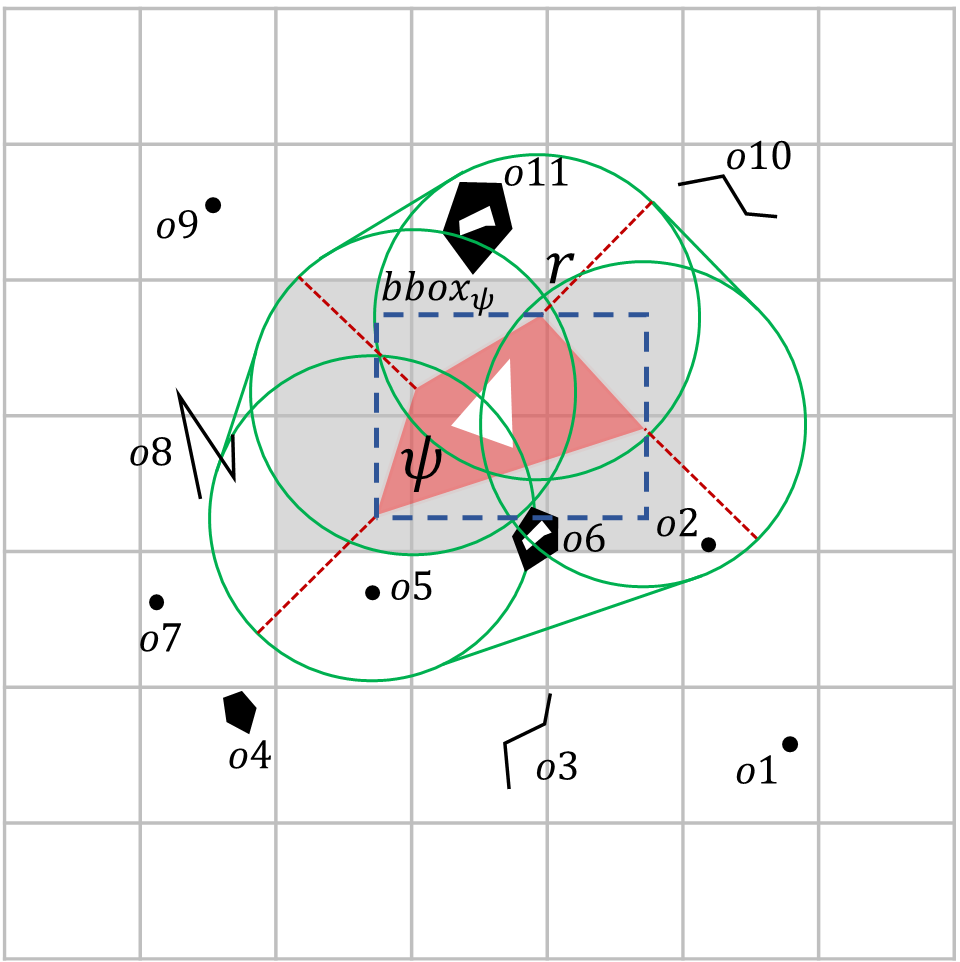
Figure 1 shows the architecture of GeoFlink consisting of spatial stream layer and real-time spatial query processing layer. Indexes are indispensable for efficient query processing and pruning. To enable real-time processing of spatial data streams, a lightweight logical grid index is introduced in this work which mainly works at the spatial stream layer. GeoFlink assigns grid-cell IDs to the incoming stream tuples based on which the objects are processed, pruned and/or distributed dynamically across the cluster nodes. GeoFlink supports spatial range, spatial kNN and spatial join queries on Point, LineString, Polygon, MultiPoint, MultiLineString, and MultiPolygon spatial objects. Besides, GeoFlink provides a user-friendly Java/Scala API to register spatial continuous queries (CQs).
GeoFlink is good for independent spatial objects, but cannot answer queries on moving objects' trajectories, where a trajectory can be defined as a sequence of points generated by a moving object ordered by timestamps. E.g., Trajectories of vehicle, robot, aircraft, human, etc. To enable support of trajectory stream processing, we extended GeoFlink and proposed TStream. TStream is a trajectory stream management system. It shares a few software components with GeoFlink. Precisely, TStream adds a set of trajectory management components to GeoFlink. Both share data types (spatial objects classes), grid index, and an overlapping set of queries, that is, spatial range, kNN and join queries on streaming data. However, GeoFlink queries process the input stream as independent spatial objects, whereas TStream queries process the input stream as trajectories. The input to and output from GeoFlink are spatial data streams of independent spatial objects. On the other hand, TStream takes trajectory streams as input and produces sub-trajectories' stream as output.
Distributed, Continuous and Real-time Trajectory Similarity Search
[ISPDC 2024]
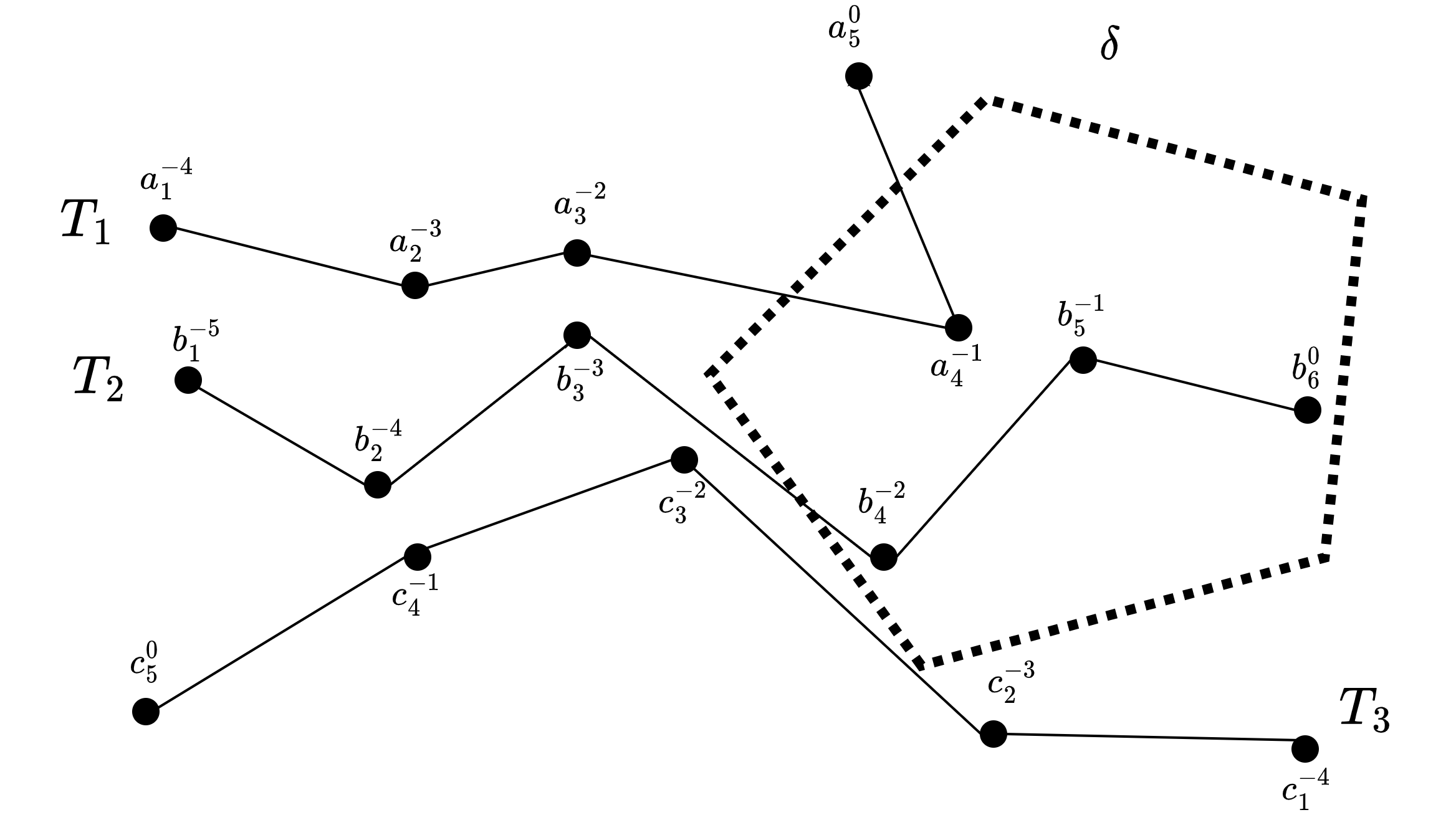
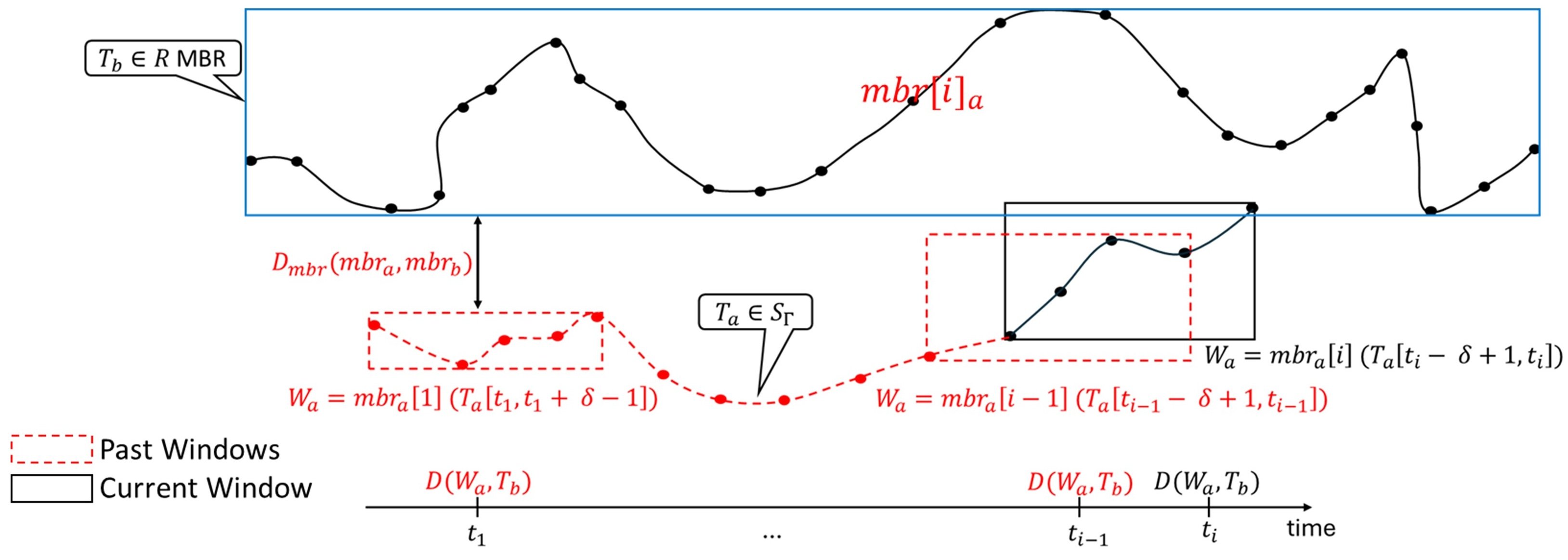
As smartphones and smartwatches become equipped with GPS, billions of trajectories are being continuously generated. Many smartphone applications need users' movement trajectories in real time to provide them useful services, for instance, ride sharing, traffic congestion prediction, emergency evacuation, etc. Trajectory similarity involves the process of comparing points between two trajectories to identify and capture similarities between them. It is a fundamental query in majority of trajectory queries and applications. Due to its importance, one can find several trajectory similarity approaches in literature dealing with full and partial trajectory matching. These approaches, given sets of trajectories P and Q, and a threshold T, finds all trajectory pairs from two sets whose similarity exceeds T or whose distance is less than T. Numerous applications require real-time and continuous trajectory similarity search. For instance, in a disaster evacuation scenario, it is essential to continuously monitor users' trajectories to devise personalized evacuation plans. Additionally, to handle the processing load of millions of simultaneous trajectories, a scalable solution becomes imperative.
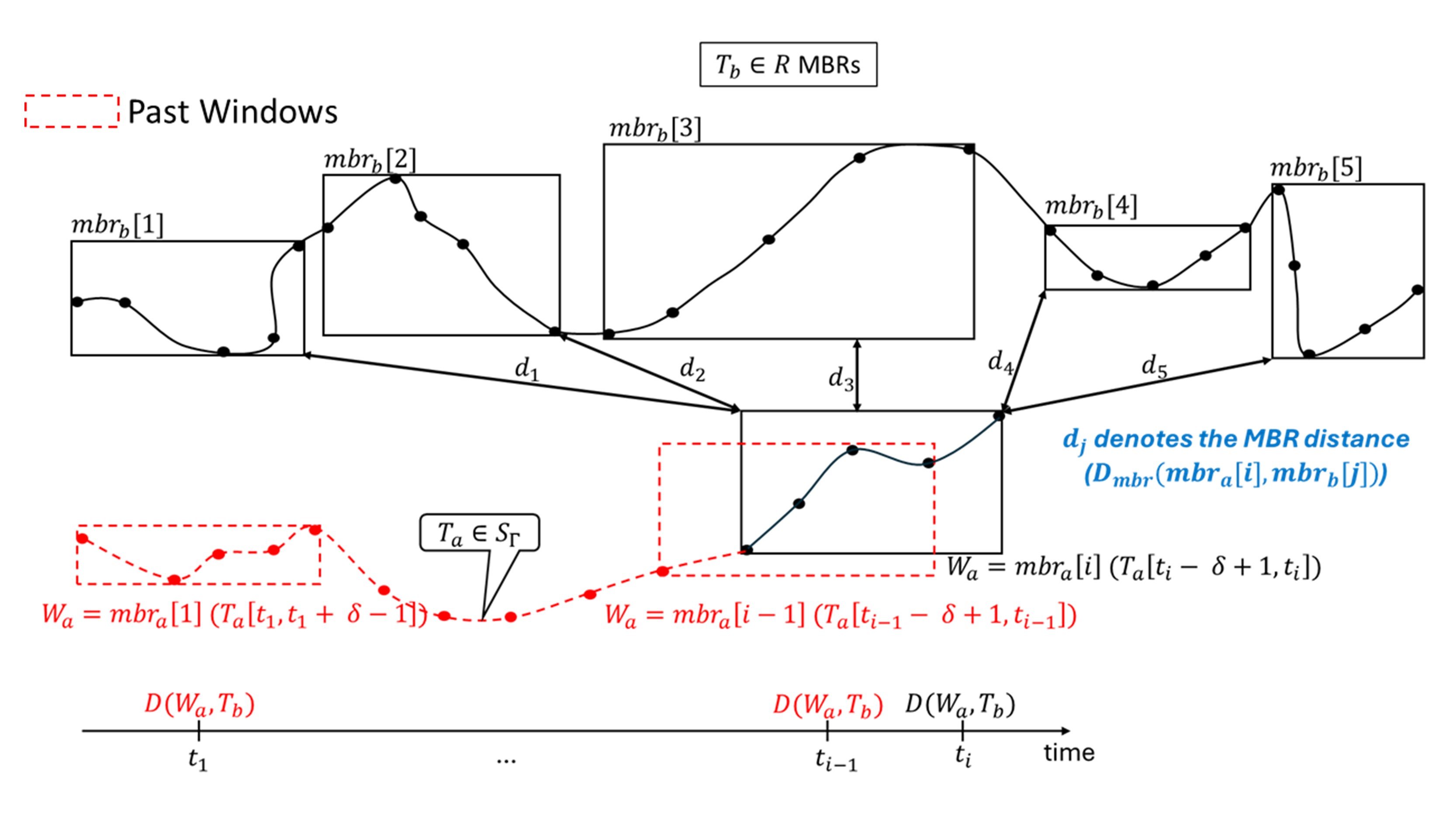
To this end, this study introduces a distributed, continuous, and real-time trajectory similarity search. We assume that new points of trajectories generated by multiple moving objects are merged into a single combined continuous trajectories stream S. Given a trajectories stream S, a static trajectory store (R), and a threshold T, continuous and real-time trajectory similarity search finds all the trajectories pairs continuously and in real-time from S and R whose distance is less than T. To reduce the similarity search cost, we utilize a tree-index. The index helps in identifying the candidates from trajectory store, thus reducing the similarity evaluation cost. This work proposes the following two index-based trajectory similarity search approaches for trajectory streams.
- Indexed Trajectories Store (ITS): R trajectories (T_b∈R) are indexed using R-tree for efficiency TS search
- Indexed Split Trajectories Store (ISTS): R trajectories (T_b∈R) are partitioned to construct R-tree for efficient pruning and TS search.
3D geometric deep learning for Visual and Geospatial Analytics
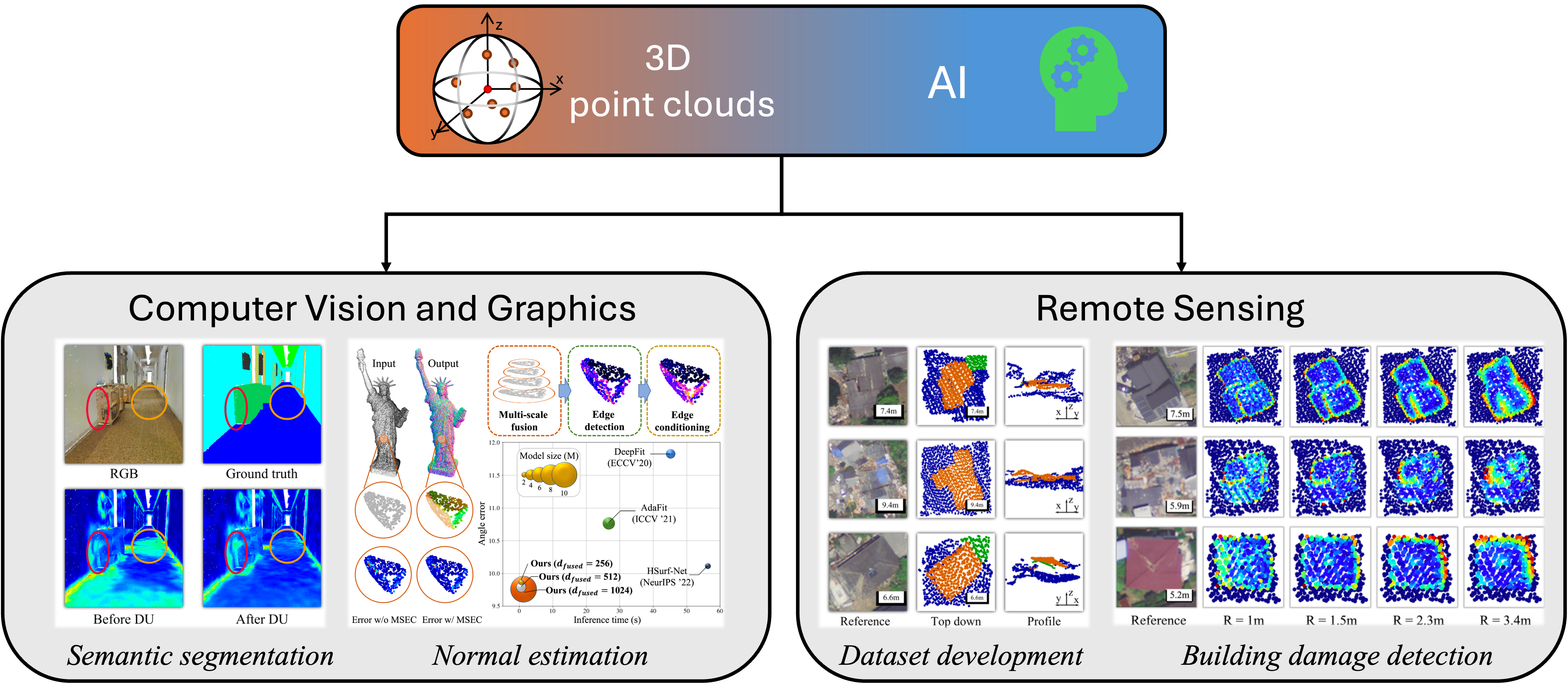
Highlights:
- Developing 3D deep learning algorithms that operate on point cloud data from diverse sources, including synthetic datasets, indoor scans, and airborne surveys.
- Applying these advanced algorithms to a range of applications, such as computer vision, graphics, and remote sensing.
Cell-Level Trajectory Prediction Using Time-embedded Encoder-Decoder Network
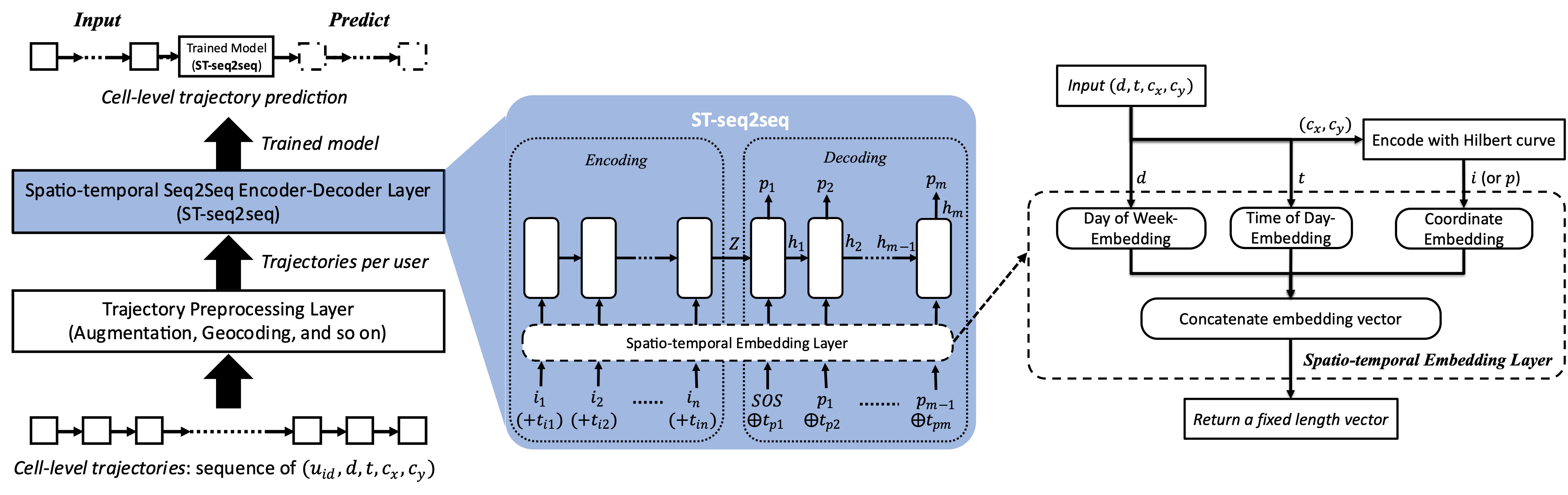
- Predicting human mobility is essential in various domains and applications (e.g., urban planning) and is one of the fundamental research topics in GIS. However, how to utilize irregular temporal information (i.e., the sampling time of coordinates is not regular) has not been studied enough.
- We proposed ST-seq2seq, a model that uses coordinate and time information to predict trajectories with non-constant temporal granularity by using embedded vectors that divide the time and day information. The ST-seq2seq is designed to predict irregular temporal information by adding a layer of temporal information embedding to the structure of the underlying seq2seq encoder-decoder network.
- Took 7th place in HuMob Challenge 2023 (https://connection.mit.edu/humob-challenge-2023/)
PinSout: Automatic 3D indoor space construction from point clouds with deep learning
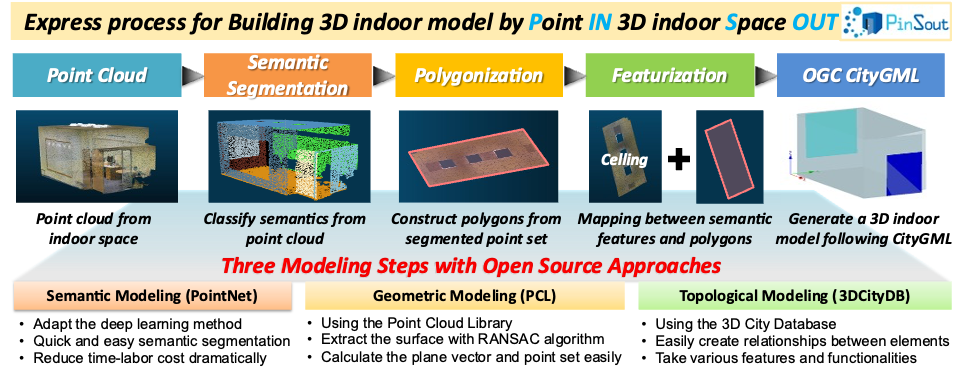
- Background: Creating a 3D model (or map) from point cloud data is a highly time-consuming and labor-intensive task
-
Proposed methods: PinSout (Point in and 3D indoor space out)
- Proposed three modeling steps (Geometric, Semantic, and Topological modeling) to generate a 3D model from a raw point cloud
- Make an approximate 3D geometry for room space to avoid noised and missed data
- Generate semantic indoor map data as OGC CityGML LoD4 data
Source code: https://github.com/aistairc/PinSout
Constructive Dialogue Modelling
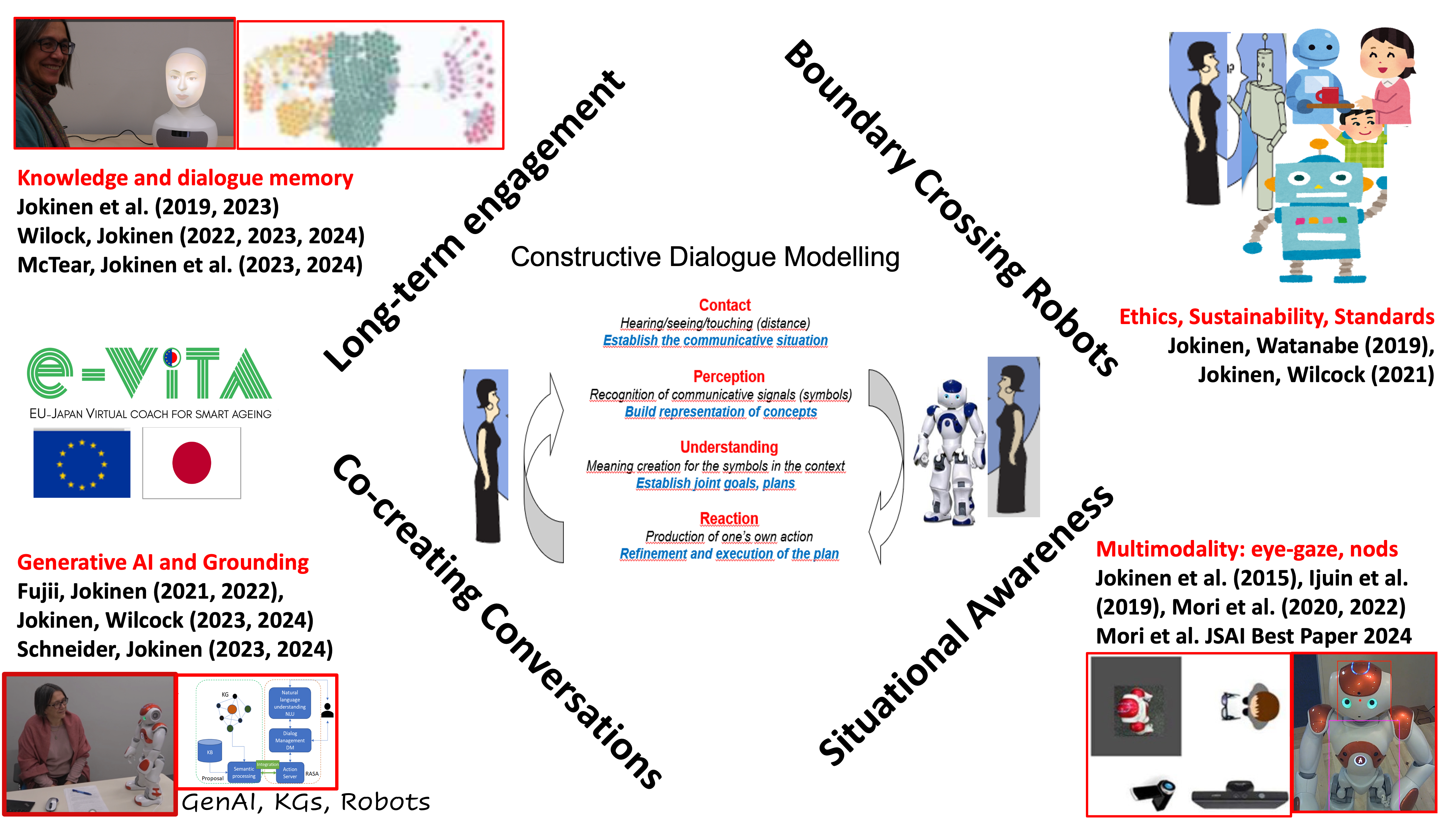
Through the years, our investigations have explored natural language and multimodal interaction including human-human interaction (HHI) and human-robot interaction (HRI). The research is multidisciplinary and concerns the methods, means, and enablements how people engage with each other and interact with big data in cyber-physical spaces using natural language. The focus has been Constructive Dialogue Modelling and the enablements of communication. Our research has concerned Situational Awareness through experimental studies on multimodal signals (eye-gaze, nodding, gesturing) and using the AICO corpus collected on HRI and HHI interactions. Check our papers at ACII, HAI, ICMI, LREC, JSAI.
Our research on Co-creating Conversations aims to establish a shared context and mutual understanding among the participants. Through experiments using different spoken dialogue platforms, we have developed dialogue systems which exemplify language-capable robots in various application scenarios such as instructing novice care-givers in care-giving tasks, providing information, and coaching elderly people for active healthy living. Recent research has focussed especially on the use of Generative AI in the grounding process and exploring challenges and opportunities to integrate GenAI, HRI, and knowledge graphs for reliable as well as smooth communication. For more details, please refer to our papers in HRI, RO-MAN, SIGDIAL, IWSDS, ICAART, ECAI, and IJAI. Long-Term Engagement addresses real-world situations where interactions are not only one-time question-answer pairs, but more personalised interactions over time. Our research has explored types of knowledge and construction of dialogue history. We have adopted knowledge graphs and graph databases for storing and representing this knowledge. Our papers in HCII, RO-MAN, IJCAI, and HRI describe this work.
Finally, the concept of "Boundary Crossing Robot" was introduced in our studies back in 2019. It refers to the new reality where social robots are becoming widespread, prompting users to reconsider the boundaries of interacting with robots. In particular, the concept encourages discussions on ethics, privacy and standardisation, as well as the sustainability of application development and the role of language-capable robots in future society. Our research has practical implications across different domainswhere interaction between users and AI agents is important. A recent example of this is our participation in the large EU-Japan project e-VITA which focussed on coaching for elderly people on active healthy living.