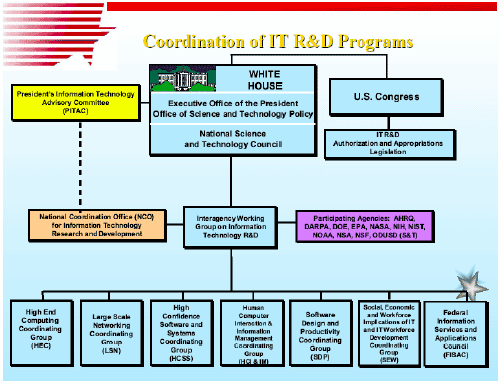
図1.1 NITRD推進体制
(National Coordination Office(NCO): メFederally-Funded Information Technology Research and Developmentモ, Jan 9 2001
第2編 先端情報技術の研究開発動向と諸外国の情報化政策
1.1.1 米国のハイエンドコンピューティング研究開発動向
(1) FY2002 Bluebookにみる政府支援のIT研究開発
a) 推進体制
ブッシュ政権初のFY2002 Bluebookは、2001年8月に開示された。政権が民主党から共和党に交代しての最初であり、内容に期待したが、FY2001
Bluebookと比較して、1/4の50ページと簡素化されている。
内容は、具体的な研究内容の紹介が多かったFY2001とは異なり、どのような目的でどのようなブレークスルーを目指すかといった一般受けのする表現に変わっている。基本的な枠組みは共和党になったからといって大きくは変わらず、従来の枠組みを踏襲している。従来の省庁間をまたがる推進体制と、6つのPCA(Program
Component Area)自体も変化していない。全体の推進体制を図1.1に示す。
図1.1 NITRD推進体制
(National Coordination Office(NCO): メFederally-Funded Information Technology
Research and Developmentモ, Jan 9 2001
NITRD(Networking and Information Technology and Development)計画は、2001年9月に下院を通過したNITRD法案に基づくが、上院を通過していないので正式な法律にはなっていない(長期のIT研究開発予算が認可されたのでは無いと言うことであろう)。NITRD計画の研究開発実体は、次の6つのPCAで推進されており、以下のグループ(Coordination Group)がある。
| ① | ハイエンドコンピューティング(HEC: High End Computing) ここは更に2つに分かれている(図1.1には記述はされていない)。 |
|
|
| ② | 大規模ネットワーク(LSN: Large Scale Network) |
| ③ | 高信頼性ソフトウェアとシステム (HCSS: High Confidence Software and System) |
| ④ | ヒューマンコンピュータインターフェイス及び情報管理(HCI&IM: Human Computer Interface and Information Management) |
| ⑤ | ソフトウェアの設計と生産性(SDP: Software Design and Productivity) |
| ⑥ | 社会、経済及び労働力の面から見たIT労働力開発の意味(SEW: Social, Economic and Workforce Implication of IT and IT Workforce Development) |
b) High End Computing予算規模
既にNITRD FY2003の予算要求は発表されているが、詳細のIT研究開発予算の配分はこれからになる。よって、FY2002の各省庁の予算要求額を表1.1に示す。
表1.1 NITRD計画 FY2002年度予算要求額
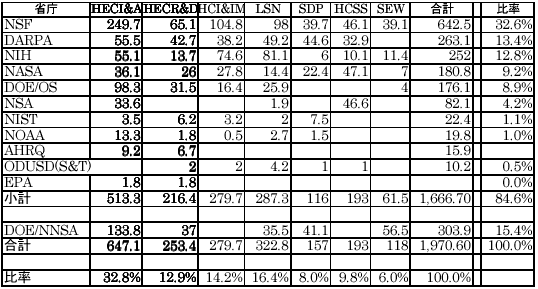
NSFが最大の予算を使い、IT関連の取りまとめ的な役割を果たしている。FY2002のHEC関連であるHEC I&及びHEC R&Dの予算要求額は合計で900.5Mドルであり、IT関連予算の50%弱を占める。米国がもっとも重視していることがうかがえる。
FY2003は、PCA毎の分類はまだであるが、省庁毎の要求予算は公表されており、NITRD総額ではFY2002実績値の3%増加の1,890Mドルになっている(表1.2)。
( http://www.ostp.gov/html/NetworkingITR&D.pdf
)
| 2002 ($M) |
2003 ($M) |
増加率 | |
| National Science Foundation | 676 | 678 | 0% |
| Health and Human Services | 310 | 336 | 8% |
| Energy | 312 | 313 | 0% |
| Defense | 320 | 306 | -4% |
| NASA | 181 | 213 | 18% |
| Commerce | 43 | 42 | -2% |
| Environmental Protection Agency | 2 | 2 | 0% |
| TOTAL | 1,844 | 1,890 | 3% |
c) ハイエンドコンピューティング(HEC)の目指すブレークスルー
FY2002 Bluebookでは中長期の研究課題を、10の研究のチャレンジ課題と7つの国家的グランドチャレンジ課題の2つのカテゴリに分けてまとめている。
ここでは、HECで特に関係の深い4つの研究チャレンジ課題について、各々が追求するブレークスルーを示す。
① 次世代コンピューティングとデータ記憶技術
② シリコンCMOS における障壁の克服
| − | 量子コンピューティング |
| − | 生物ベースコンピューティング |
| − | 「スマートファブリック」:織り合わせ形バッテリ、光ファイバーケーブル、金属コネクタ等の技術を利用して、科学者は、数十Tera-ops クラスの処理(今日の大型スーパーコンピュータの規模)を行うのに充分なプロセッサを浮き彫り加工し、人が身につけられる織物を作ることが可能である。 |
| − | 分子電子工学。軍事用次世代戦略コンピューティングのための極度に速く、高密度の処理能力を持った分子スケールの計算 |
③ 21世紀のための多目的、安全、拡張可能なネットワーク
| − | 光ネットワーキング(フロー/バーストとパケット交換、アクセス技術、毎秒ギガビットレベルのインターフェイス、プロトコルの階層化) |
| − | ネットワークのダイナミクスとシミュレーション(自動管理、自動リソース回復、ネットワークモデリング) |
| − | 耐故障性と自律的管理 |
| − | リソース管理(発見と仲介、事前予約、共同スケジューリング、ポリシー駆動型の割当メカニズム) |
| − | 無線技術(発見、共存とコンフィギュレーションのための技術標準) |
| − | 帯域幅に対する要求を支援する能力の増強 |
| − | 頑強性の改善、数十億のデバイスの一時的相互作用の取扱いとネットワークの遠端からのアクセスを最大化するためのネットワークの増強と拡張 これには、ユビキタスブロードバンドアクセス方式、無限ネットワーキング、セキュリティとプライバシー、ネットワーク管理等の研究がある。 |
| − | 地球規模のネットワークおよび情報インフラストラクチャを理解すること(エンドトゥエンドパフォーマンス、バックボーン構造、アプリケーション) |
| − | 分散型データインテンシブコンピューティング共同研究、コンピュータ操縦による科学的シミュレーション、遠隔ビジュアライゼーション、遠隔機器の操作、大規模分散型システム |
④ 科学と工学における米国の強みを維持するための先進的IT
d) FY2003予算に見る研究開発目標の特徴
FY2002 Bluebookは同時多発テロ以前にまとめられたものであり、この対策は意識的には加味されていない。先に述べたOSTPのFY2003予算の分析資料には、テロ以後の対策を含むNITRDの目指す重点目標が簡潔にまとめられている。詳細は今後のFY2003
Bluebookにまとめられるはずであるが、それの予告が見られるので、ここに紹介する。
次の様な技術の開発を達成することを重点課題に挙げている。
| ① | エンドツーエンドの光ファイバーネットワーク ネットワークバンド幅とネットワークセキュリティの大幅の向上をもたらす。 |
| ② | クラスタおよびGridコンピューティングを可能にする新しい技術 科学研究ネットワークのための高性能計算機への初めてのアクセスをもたらす。 |
| ③ | ネットワークセキュリティプロテクション技術で次のようなものを含む。 不正侵入検出、リスクおよび弱点解析、大規模情報レポジトリーの管理、運用 |
(2) ハイエンドコンピューティング分野の新しい動向
— 実用化に向かう超並列、超分散コンピューティング —
a) SC2001に見る動向
SC Globalといって、Access Gridのテクノロジーを利用した遠隔会議による参加も初めて行われ、世界40カ所以上と接続された。同時にGrid2001が特別ワークショップの形で丸1日開催された。展示会場でもSUNのメSun
Powers the Gridモなるキャッチフレーズ等Gridにあやかった展示が多く見られ、SC2001の主役はGridの感が強かった。
SC2001の前日11/9に発表されたTop500(18th版)においても超並列マシンASCIが上位を独占し、近年PCクラスタもその順位をのばしており、ハイエンドコンピューティングの流れはますます超並列、超分散化が加速している。
なお、SC2001の報告については恒例になった東大小柳教授のレポートが詳しい。(http://olab.is.s.u-tokyo.ac.jp/~oyanagi/reports/SC2001)
b) 超並列コンピューティング
| ① | TOP500にみる超並列マシン SC2001と同時に発表されたTop500(http://clusters.top500.org/)によると超並列マシンが上位を占め、特に近年はASCIマシンの独壇場であった。Top1は昨年と同様のASCI Whiteである(実行性能は昨年の4.9 Tflopsから7.2Tflopsに向上しているが構成は同じ)。表1.3にTop5を示す。第2位にクラスタシステムが入って来ているのが注目すべき流れである。 |
| 順位 | メーカ | マシン | Rmax (GFlops) |
設置場所 | CPU数 |
| 1 | IBM | ASCI White,SP Power3 375 MHz |
7,226 | Lawrence Livermore National Laboratory | 8,192 |
| 2 | Compaq | AlphaServer SC ES45/1 GHz | 4,059 | Pittsburgh Supercomputing Center | 3,024 |
| 3 | IBM | SP Power3 375 MHz 16 way | 3,052 | NERSC/LBNL | 3,328 |
| 4 | Intel | ASCI Red | 2,379 | Sandia National Labs | 9,632 |
| 5 | IBM | ASCI Blue-Pacific SST,IBM SP 604e |
2,144 | Lawrence Livermore National Laboratory | 5,808 |
| ② | Peta Flopsを目指すBlue Geneプロジェクト 従来、IBMが独自に開発を進めていたBlue Geneプロジェクトであるが、2001年11月にDOE/NNN(Lawrence Livermore National Laboratoryが対応)と共同開発を進めることを発表した。2005年に200Tflopsを目指す。 (http://www.research.ibm.com/bluegene/BG_External_Presentation_January_2002.pdf) 現在最速のスーパーコンピュータ(Option Whiteか)に比べて性能では15倍速く、電源容量は1/15、大きさは1/50から1/100と豪語している。このあと更にBlue Gene計画は1Peta Flopsを目指す(規模縮小したとの声も有るが定かではない)。 |
| ③ | ベクター型超並列マシン「地球シミュレータ」 ベクター型プロッセサを超並列に利用し40Tflopsと汎用スーパコンピュータ世界一の性能を叩き出す地球シミュレータが横浜市の海洋科学技術センター内に2002年3月末に完成した。次回(2002年6月)19th版のTop500で第1位が期待される。 今やベクター型は日本しか作っておらず、トレンドから外れた感もあるが、地球シミュレータの実績如何では、見直しの可能性もある(がんばれ日本のスーパーコンピュータ!)。 |
| ④ | 専用スーパーコンピュータ 汎用のスーパーコンピュータのコスト、性能の壁を破るべく特定分野に特化した、専用スーパーコンピュータの分野も性能向上がめざましい。SC2001でも東大の重力多体シミュレーション専用のGrape6は11.55Tflops(ピーク性能32Tflops)を達成し、昨年に続きゴードンベル賞(Peak Performance部門)を受賞した。更に2002年3月5日にはピーク性能48Tflopsを達成し、世界最高速となったと発表した。なお専用マシンの低コストについては“GRAPE6 の開発総予算はわずか5億円であり、400億といわれるASCI Whiteの約 1/100でしかない”と紹介されている。 (http://grape.astron.s.u-tokyo.ac.jp/pub/people/makino/press/2002-symposium.html) |
c) クラスタシステム動向
| ① | Top500に見るクラスタシステムの増加 今回はTop10で見ても2台のクラスタシステムがランクインした。従来はミドルクラスを占めていたが、ハイエンドの世界でも民生の部品を応用したクラスタシステムの流れが押し寄せてきている。専用部品を使用したスーパーコンピュータに対するコストパフォーマンスの良さが一番の原因であろう。表1.4に世界のTop5を示す。チップの種類を見るとCompaq社のAlphaチップがほぼ上位を独占している。 |
| 順位 | Top 500 |
メーカ | マシン | Rmax (GFlops) |
設置場所 | CPU数 |
| 1 | 2 | Compaq | AlphaServer SC ES45/1 GHz |
4,059 | Pittsburgh Supercomputing Center | 3,024 |
| 2 | 6 | Compaq | AlphaServer SC ES45/1 GHz |
2,096 | Los Alamos National Laboratory |
1,536 |
| 3 | 30 | Self-made | CPlant/Ross Cluster | 706.7 | Sandia National Laboratories |
1,369 |
| 4 | 31 | Compaq | AlphaServer SC ES45/1 GHz |
706 | Australian Partnership for Advanced Computing (APAC) |
480 |
| 5 | 34 | IBM | Titan Cluster Itanium 800 MHz | 677.9 | NCSA | 320 |
| ② | 世界最速のクラスタマシン PSC(Pittsburgh Super Computing Center)に設置されたCompaq社の民生Alphaチップを使用している。2001年より稼働し、NSFのPACI(Partnership for Advanced Computational Infrastructure)を通して、研究開発に共同利用されている(図1.2) |
 図1.2 PSCに設置の世界最速クラスタ |
ピーク性能:6.0 Tera flops メモリ:3.0 Tera Bytes ディスク:50 Tera Bytes (http://www.psc.edu/publicinfo/news/2001/terascale-10-01-01.html) |
| ③ | 日本のクラスタ動向 日本のクラスタは今のところ世界の第6位であり、生命情報科学研究センター(CBRC)が利用しているNEC製のクラスタMagi Cluster(Pentium3,933Mh)である。 なお、日本でもPCクラスタコンソーシアムが2001年10月発足し、産官学共同の促進が始まった。新情報処理開発機構(RWCP)が開発したSCoreクラスタシステムソフトウェア、およびOmni OpenMPコンパイラが中核となっている(http://www.pccluster.org/)。 |
| ④ | InfiniBand ベオウルフ型クラスタを構成する民生ネットワークとしては、GigaBit Ether, Myrinet等が使用されているが、最近InfiniBandが注目を浴びている。ネットワーク性能としては単線の2.5Gbitを1本/4本/12本で各 2.5 G bits, 10 G bits, and 30 Gbits/秒の速度を提供する。Compaq, Dell, Hewlett-Packard, IBM, Intel, Microsoft and Sun Microsystems が主体になって、1999年10月にInfiniBand Trade Associationを設立し、2000年10月に標準仕様を策定している(http://www.infinibandta.org/ibta/)。 当研究所のWGにおいても、米国でInfiniBand関連ハードウェア主体のベンチャー企業RedSwitch社のCEO Dr.Wen Leeにご講演を頂いた。米国ではInfiniBand関連の企業化が始まっている(http://www.redswitch.com/)。 現在、InfiniBAnd関連の製品は量産化されておらず、サンプル価格的なものが多いが、今後の市場拡大と価格の低下が期待される。 |
d) 超分散コンピューティング
| ① | Gridコンピューティング SC2001の展示会でも分かるように、世界中のコンピュータをつなぎコンピュータ資源を有効に活用しようと、Gridコンピューティングへの流れが加速している。ハイエンドコンピューティングの世界でも超並列を持ってしても単独のコンピュータセンターでは物理的、経済的にも制限がある。まずスーパコンピュータセンターを高速ネットワークで接続し、仮想的研究所を構築する構想から始まっている。ASCI等の超並列コンピュータ自体もその一つのノードになる。ASCI Grid Serviceという広報用CDもSC2001では用意されていた。ASCIの超高速コンピュータもポータルの一つになる。 主に計算能力資源を活用するComputational Grid、ネットワークを介してマルチメディア情報をやりとりし遠隔会議を実現するAccess Grid、大規模な高エネルギー物理のデータを扱うEU連合のData Grid等、多くのプロジェクトが世界的に行われている。 ただし、Gridはまだ公式な標準があるわけではなく、デファクトスタンダードの世界である。ソフトウェアツールキットとしてはGlobusがデファクトの位置を確立している、 今後この流れは、研究開発向けから一般ビジネスの世界に広まるのは必至であろう。 なお、産総研の田中氏が展示者としてSC2001に参加し、当研究所のWG調査報告書の第3章に、状況を詳細にレポートして頂いている。また、昨年の調査報告書に、関口委員(産総研)の報告「Gridによる世界戦略とグローバルコンピューティング技術」で動向が分かり易く紹介されている。 |
| ② | Tera Grid計画 世界最大、最高速の分散ネットワーク環境を構築すべく、NSFから53Mドルの資金提供を受け、4つの研究所(NCSA, Argonne, Caltech, SDSC)を光ファイバー高速バックボーンネットワーク(40Gbits)で結ぶ。完成時には13.6TeraFlopsのLinuxクラスタコンピュータパワーと、450TeraBytesのデータ容量と、高精細のAccess Grid環境が提供される。 (http://www.teragrid.org/index.html、http://www.teragrid.org/img/teragrid.sm.jpg) IBM, Intel, Qwest社が企業として参加しており、64Bit Itaniumチップを320個用いたIBM製のLinuxクラスタマシンが2001年10月からテストを開始した。 日本では、Top100スーパーコンピュータのうち6台が集中する、世界でも有数なつくば地区に「つくばWAN」が完成し、2001年3月22日に開通式を行った。ネットワークは10Gbpsの光ループが使われている(総容量は570Gbps)。当初はつくば地区にとどまっているが、今後、地球シミュレータをはじめ、全国の大学、研究所間の接続が検討されている。 |
| ③ |
ベンチャー企業動向 |
|
e) 量子コンピュータの動向
IBM研究グループは、2000年8月に5量子ドットの実験に成功した後、IBM Almaden研究センターとスタンフォード大学は共同で、7量子ドットの量子コンピュータにて15=3x5の因数分解に成功、と2001年12月20のNature誌に発表された。
これは、試験管に入れられた特別な分子を、核磁気共鳴装置の核スピンの傾きを制御し、計算を行うことで実現したもので、1994年に当時AT&T社のShor氏が唱えたShorのアルゴリズム(量子コンピュータは今日の汎用コンピュータに比べて圧倒的なスピードで因数分解を計算できる)の初めての実験による証明になった。
(http://www.research.ibm.com/resources/news/20011219_quantum.shtml)
研究は一歩一歩に進んでいるが、SC2001の展示でも、量子コンピュータ、分子コンピューティングはパネル展示の原理の解明段階であり、目立ったアピールはしていない。実用になる量子コンピュータの実現は、まだ長期の研究開発が必要である。米国は長期研究テーマである新しい計算基盤に向けて、研究開発投資を怠りなくやっている。
f) 超並列、超分散を容易に開発できるソフトウェアの研究開発動向
FY2001よりPITACのソフトウェアの生産性に対する憂慮からの勧告に従い、IT R&D計画にSDP(Software Design and
Productivity)プログラムコンポーネントエリアが新設された。FY2002 Bluebookでも、研究チャレンジ「現実世界のためのソフトウェア作成」にて、重要テーマにあげている。目標としては次がある。
| ① | ソフトウェアとシステム設計の科学
|
||||||||
| ② | 工学的プロセスの自動化
|
||||||||
| ③ | パイロットアプリケーションと実験による評価
|
研究課題の中には超並列、超分散を意識した研究開発内容が多々見られる。単体によるハードウェア高速化の限界の打開が超並列、超分散に向かっているので、ハードウェアの困難さ以上にソフトウェアにその負担が大きくふりかかってきている。特定の分野(粗な結合で超並列、超分散でも性能が出やすいところ)では実用になっているが、これを汎用コンピューティングの世界に向けて実用化するには、更に長期の研究が必要である。
1.1.2 ハイエンドコンピューティング研究開発動向
ここでは当研究所のWGの各委員および外部講師による調査報告の概要を示す。
(1) アーキテクチャ&新計算モデル
① 半導体性能向上神話崩壊後のアーキテクチャ
CMOS LSIの動作速度はプロセスの進歩につれて向上を続け、新しいプロセスを利用することは、それだけで性能の向上につながった。これは、微細加工技術の発展と共に、電源電圧を落すことができれば、論理ゲートの遅延を減らすことができたことによる。ところが、2001年、プロセスが0.18umから0.13umに進む際、電源電圧を低くすることがほぼ限界に達すると共に、LSIチップ内の遅延の支配的要因が、ゲート遅延から配線遅延に移行した。このため、銅配線などを用いない限り、新しいプロセスを単に利用するだけでは、性能は全く上がらなくなるに至った。半導体性能向上神話は崩壊し、今年から新しい時代に突入したのである。今後、CMOS
LSIプロセス技術に画期的なブレークスルーがない限り、この傾向は続くと考えられる。
本レポートでは、半導体性能向上神話が崩壊した「新しい時代」を迎えて、アーキテクチャをいかに構成すべきかを提言する。まず、新しい時代に高い性能を実現するアーキテクチャについて述べ、ますます発展が予測されるReconfigurable
Architectureについてまとめる。
② メガスケールコンピューティングの構想
筆者らは科学技術振興事業団の戦略的基礎研究推進事業による研究プロジェクト「超低電力化技術によるディペンダブルメガスケールコンピューティング」を実施している。このプロジェクトは、百万プロセッサ級のメガスケールコンピューティングを真に実現するための基盤技術を追求するものであり、そのためにコモディティ技術、すなわち高性能計算のみをターゲットとしない一般性の高い技術をベースとした研究開発を行う。
プロジェクトでは、メガスケールコンピューティング実現の鍵は、①feasibility、②dependability、③programmability
の3点にあるとし、それぞれ、①ハード/ソフト協調による低電力高性能プロセッサ、②マルチポートネットワークとミドルウェアによる高信頼化、③グリッド/P2P技術をベースとした高粒度大規模並列プログラミングの研究を行う。また、これらの技術を統合したプロトタイプとして、数千プロセッサ級の大規模低電力クラスタの構築も計画している。
③ PCクラスタの現状と今後
現在PCクラスタを取り巻く環境が激変しつつある。1つは、PCクラスタを構成する要素部品である、CPUとネットワークの高性能化である。現在入手できる最高速のPC向けCPUによれば、単一で1GFlopsを越える性能を得ることが出来る。更に、ネットワークの性能もCPUの外部バス性能と匹敵するスループットを達成している。つまり、ネットワークをこれ以上高速化しても、メモリのボトルネックによって律速されることになる。
一方、PCクラスタを利用する環境として従来は、計算センタ内の1つの高性能システムとの位置づけであった。しかし、高速インターネットの発達により、地理的に分散している複数の計算センターを接続し、全体として運用する、いわゆるグリッドコンピューティングを構成する要素システムの扱いを受けるようになってきた。
PCクラスタシステムを上の二つの観点から分析し、今後の動きを考える。
(2) 基本ソフトウェア&ミドルウェア
① 手続き間解析の動向 〜コンパイラとその周辺〜
手続き間解析とは、手続き(関数、サブルーチン)の解析情報を、その手続きの呼び出し点で利用できるようにするコンパイル技術のことである。これによってプログラムの解析精度が向上し、プログラムを最適化する機会が増加することが期待できる。広い意味では、インライン展開も手続き間解析の一つと考えられるが、リカーシブな呼び出しに対応できないなど、適用範囲が狭い点が課題である。これに対して、狭義の手続き間解析はその一般性から、FortranのみならずC++やJavaに対する最適化コンパイラでも徐々に採用されつつあるなど、広がりをみせている。
本稿では、Fortranコンパイラにおける手続き間解析、及び、ツールにおける手続き間解析の利用に関する動向を、具体的な事例を通して紹介する。
② 自動並列化コンパイラによるSMP上での粗粒度タスク並列処理
ここでは、SMP上におけるOSCARマルチグレイン並列化コンパイラを用いた粗粒度タスク並列処理について述べる。現在、サーバアーキテクチャの主流であるSMP上での自動並列化コンパイラを用いた並列処理では、ループレベル並列処理の性能が飽和状態に達しており、その限界を越えるため粗粒度タスク並列処理が注目されている。OSCAR
FORTRAN コンパイラにおける粗粒度並列処理手法では、ソースプログラム中のサブルーチンループ・基本ブロック間の並列性を抽出し、各種SMP上で粗粒度タスク並列化を実現するために、OpenMPを用いたワンタイムシングルレベルスレッド生成手法を用いている。さらにSMPで問題になる共有メモリアクセスオーバヘッドを軽減するため、複数タスク間での共有データの授受にキャッシュを最大限利用するデータローカライゼーション手法を併用することで、さらなる性能向上を図ることができる。ここでは、これらの技術を用いて、SMPサーバ
IBM RS6000 SP 604e High Node、SMPワークステーションSUN Ultra80 での粗粒度タスク並列処理を行った結果について述べる。
③ P2Pの理念および実現技術:SIONetの全貌
筆者は、1998年にブローカレス型探索モデル(ブローカレスモデル)を提案して以来、その実現技術として「意味情報ネットワーク(SIONet Semantic
Information-Oriented Network)」をこれまで提案してきた。そして、1998年末にSIONetプロトタイプα版、1999年末にSIONetプロトタイプβ版の試作を完了した。さらに、2000年末にSIONet
ver.1.0の開発を完了した。
本稿では、ブローカレス型探索モデルを紹介することにより、「P2Pの本質」について論ずる。さらに、ブローカレス型探索モデル(P2Pモデル)の実現技術であるSIONetについて解説する。
(3) 応用システム&応用分野
① SC2001に見るGridの最新動向
Gridとは、「高速ネットワークで接続された高性能計算機、大規模データベース、特殊な装置、人的資源などの様々な資源を柔軟に、容易に、安全に、統合的に、そして効果的に利用するためのネットワーク利用技術」である。本稿では、2001年11月に米国コロラド州デンバーで開催された高性能計算および高性能ネットワークに関する国際会議であるSupercomputing
Conference(SC 2001)における講演、技術論文、企業展示および研究展示の内容をふまえ、Gridの現状および最新動向について報告する。
本報告においては、①Gridにおける低レベルなソフトウェアの基盤として事実上の標準になっているGlobus Toolkit、②ユーザに対して簡便なインターフェイスを提供するGrid
Portalシステム、③高性能インターネット会議システムであるAccess Gridおよびそれを利用してSC 2001期間中に開催されたイベントSC
Global、の3件に焦点をあててGrid技術および研究動向に関する報告を行う。今後各地で実際のGridテストベッドの運営が進められると予想されるが、相互利用の可能性を高める意味でもGlobus
Toolkitがその基本ソフトウェアとして用いられ、ユーザに対してより上位なインターフェイスを提供する高レベルミドルウェアやWebインターフェイスを提供するPortalシステムの研究開発が活発化すると予想される。また、Gridの本質である仮想的な組織(Virtual
Organization)の運営においては実際に顔をあわせてのミーティングが重要になると思われ、Access Gridのようなシステムは有用であり、今後Gridの技術を取り込んでより高機能、高性能なシステムの開発が望まれる。
② 地球シミュレータ開発を終えて
平成9年度から開発を進めてきた地球シミュレータは、平成14年2月にピーク性能40テラフロップスの世界最高速を達成し完成した。そのハードウェアは、640台の計算ノードをフルクロスバスイッチで結合したものであり、大規模な並列計算機システムを利用するための特徴あるプログラミングインターフェイスを具備している。
本稿では、地球シミュレータのハードウェア及びソフトウェアの概要、並列プログラミングインターフェイス、及びいくつかのシミュレーション結果について述べる。
③ 高速ネットワーク環境下における高度医療アプリケーション
がん治療法の一つである粒子線治療は、ヘリウム、炭素、ネオンなどの重粒子線を患部に集中して照射し、周辺の正常細胞への影響を最小限に抑え、患者の早期社会復帰を可能とする非常に有効ながん治療方法である。この粒子線を用いたがん照射治療を普及させるためには、遠隔地の複数の医療機関から高速なネットワークを介して、重粒子線がん照射施設の計算サーバにより、照射施設のノウハウを利用して患者毎に最適な照射方法を得る治療計画を立案できることが望ましい。このような高速なネットワークの利用法はまだ実現例に乏しく、基本的な性質の解明も進んでいない。インターネットの普及が進み、ネットワークを利用する研究者にも利便性を提供しているが、一方ではネットワークの輻輳が発生して、研究環境が悪化している例がある。またネットワークに不正に進入する事例が多数発生しており、医療関係の情報のようにプライバシーを守るべき対象を安全に保護する技術が必要不可欠となっている。このような状況から、インターネットにおける信頼性・高速性・利便性・安全性に関する種々の問題点を解決するために、これらについて極めて高度な要求を持つ遠隔地重粒子線がん照射影響シミュレータを業務として想定し、ギガビットレベルネットワークに向けた信頼性・高速性・利便性・安全性を確立することを目指して、高度医療ネットワークに関する研究が行われている。