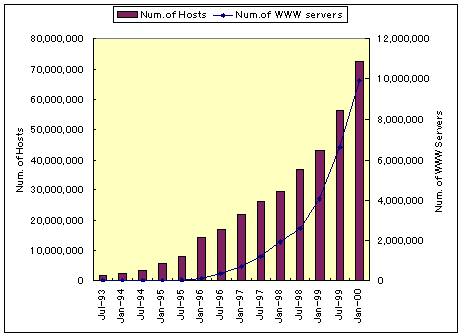
図3.5-1 インターネットに接続するホスト数とWWWサーバ数の推移
(米国Internet Software Consortium, 英国Netcraft社が公表するデータを元に作成)
3.5 Webデータ収集の現状と課題
本節では、WWWサーバ上のデータを例として取り上げ大規模なデータを高速に収集する手法の現状と今後の課題を明らかにする。特に、WWWはインターネットの一般市民への浸透に伴って急速に広まっており、WWWを通して世界中に分散するデータを巨大データベースとして活用できれば、その経済的効果は莫大なものになると推測される。
3.5.1 インターネットとWWWの発展
インターネットに接続するコンピュータ台数(ホスト数)は、米国Internet Software Consortium(http://www.isc.org/)が半年毎に公表しているデータによれば、2000年1月現在で約7200万台である。また、英国Netcraft社(http://www.netcraft.co.uk/)が毎月公表しているデータによれば、WWWサーバ数は2000年1月現在で995万台であり、全ホストの約14%がWWWサーバとして情報を発信していることになる。図3.5-1に半年毎のインターネット接続ホスト台数とWWWサーバ数の推移を示す。また、インターネットに接続するホスト数、ドメイン数、WWWサーバ数の毎年の増加率(前年比)を図3.5-2に示す。なお、ドメイン数は、edu,com,gov,mil,org,int,netで終わるドメインについては第二レベルで、それ以外のドメインは第三レベルで計算した。
図3.5-1 インターネットに接続するホスト数とWWWサーバ数の推移
(米国Internet Software Consortium, 英国Netcraft社が公表するデータを元に作成)
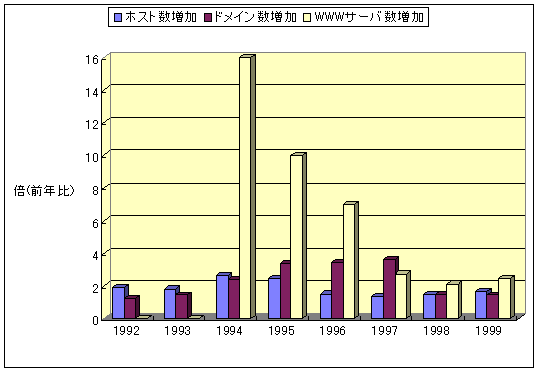
図3.5-2 ホスト数,ドメイン数,WWWサーバ数の毎年の増加率
(米国Internet Software Consortium, 英国Netcraft社が公表するデータを元に作成)
1994年にWWWサーバ数が急増したのは、この年にNetscapeのバージョン1の公開に伴って急激にユーザ層が広がり、それに伴ってデータを発信するWWWサーバ数が増加したためだと考えられる。その後、WWWサーバ数の増加率は減少したが、1998、1999年とほぼ前年比2倍で推移している。一方、ホスト数及びドメイン数の増加は1998年、1999年とほぼ前年比1.5倍で推移している。
3.5.2 WWW情報検索サービスの動向とWWWサーバから発信されるデータ量
NEC北米研究所の Steve Lawrenceらの統計的調査によれば、1999年2月現在のWWWサーバから発信されるデータ量は約8億ページと推測される[1]。テキストファイルのみのデータ量は15TB(タグ部分を除けば
6TB)であり、平均18.7KB/page、メタタグを持つページが1ページ以上存在しているサーバ数は全体の34.2%、XML(Dublin Core)を用いているのは全体の0.3%であるとの結果が得られている。これらの推定の詳細は文献[1]に詳しいが、全体のページ数推定は、複数の検索サービスに対して同じQueryを送り、得られた検索結果の重複度から統計処理し算出している。また、各ページの平均の大きさ等は、実際に2500のWWWサーバのデータを収集し算出している。
1999年2月時点でのWWWサーバ数は、英国Netcraft社の調査によれば430万台であり、430万台であり2000年1月にはこれが956万代になっていることから推測すると、2000年1月現在でのWebページ数は全世界で17.8億程度となる。
図3.5-3に、2000年1月現在での有名なWWW情報検索サービスサイトが収集しているWebページ数(各社の公表値)を示す。これからわかるように、現在最も多くのページを収集しているFAST(http://www.alltheweb.com/)でも、3億ページ(全体の約18%)にとどまる。一方、1997年末時点でのWebページ数は3.2億、この時点で最も多くのページを収集していたのはAltaVistaの1.2億ページであり、全体の約38%をカバーしていた。このように、年々Webページ全体に対するカバー率は低下の一途をたどっている。
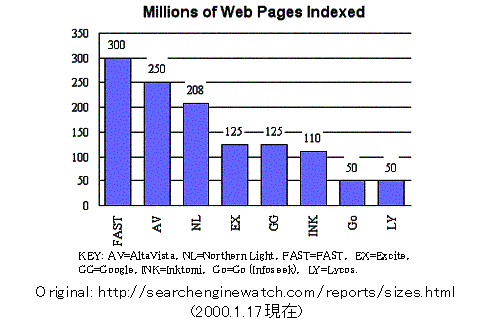
図3.5-3 WWW情報検索サービスが収集し検索対象としているWebページ数
3.5.3 Webページ収集と問題点
Webページは、一般的にはWebロボットと呼ばれるプログラムを使って収集する。収集の開始点となるURLをWebロボットに渡すことにより、Webロボットは、その開始点となるURLからhttpプロトコルを用いて順次リンクをたどりWebページを収集する。
公開されているデータ(http://info.webcrawler.com/mak/projects/robots/active /html/)によれば、2000年1月現在でのWebロボットの種類は218である。また、電子技術総合研究所(http://www.etl.go.jp)へのアクセスログを元に調査したところ、常に20を越えるWebロボットがWWWサーバのデータ収集を毎日行っていることが判明した。さらに、電子技術総合研究所に対してアクセスのあるWebロボットを調査(1999年7月12日〜18日)したところ、全アクセスの37%がWebロボットによるものであった。WIDEが集計した統計(http://www.wide.ad.jp/)によれば、httpプロトコルは、全プロトコルの70%程度を占めているため、電子技術総合研究所のWWWサーバへのロボットのアクセスが平均的なものであると仮定すると、「インターネットの約4分の1はWebロボットが利用している」と推測することができる。
このように、1)20を越えるWebロボットが同一のWWWサーバのデータを収集するのは無駄である点、2)インターネットの約4分の1をWebロボットが利用している点、3)WWW情報検索サービスがデータとして持つWebのページのカバー率が低下している点を考え合わせると、複数のWWW情報検索サービスを提供するサイトが、個別にデータを収集せず協力して高速に集めるための仕組みの構築が重要なポイントとなる。
3.5.4 分散型WWWロボットによる収集実験[2][3]
図3.5-4に示す早稲田大学、京都大学、慶応大学、北陸先端科学技術大学院大学、大阪府立大学、シャープ、日本IBM、電子技術総合研究所を中心としたグループでは、IPA独創的事業研究開発テーマ(平成10〜11年度)において、分散型WWWロボットによる実験を行っている。

図3.5-4 分散型WWWロボット実験参加者(2000年1月現在)
実験では、「国内(jpドメイン)のWWWサーバの全ページ(テキストのみ)を24時間以内に収集する」ことを目標としている。
分散型WWWロボットの構成を図3.5-5に示す。分散型WWWロボットは、図に示すように大きくPRSM(Public Robot Server Manager)とPRS(Public
Robot Server)の2つから構成され、プログラムはJavaにより記述されている。PRSMは、個々のロボットであるPRS全体を管理する。すなわちPRSMは、PRSに対して担当WWWサーバの分配、各WWWサーバとPRS間のデータ転送速度計測の指示を出す。PRSは、PRSMからの指示に基づき、データ収集、データ転送速度計測を行いPRSMに報告すると共に、PRSで新規に発見されたWWWサーバについてもPRSMに報告する。このようにして、PRSはPRSMからの指示に基づき各々互いに重複しないWWWサーバを担当しWebページを収集する。収集されたデータは、最終的に図中のSearch
Service Server(SSS)に再配布することにより、検索サービスのための索引作成などを行う。
分散型WWWロボットでは、PRSとWWWサーバ間のデータ転送速度が、全体の収集時間を決定する大きな要因となる。このためPRSの分担では、各PRSについて、Σ(PRSが担当するPRSサーバ全てについて)((PRSが担当しているWWWサーバxの総データ量)÷(PRSとWWWサーバx間のデータ転送速度))をPRSのデータ転送コストと定義し、データ転送コストが全てのPRSで均一になるようにするためのアルゴリズムを開発している[4]。
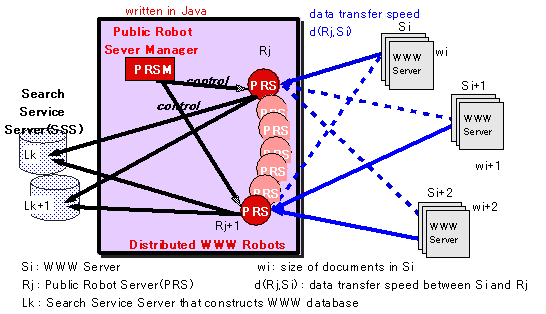
図3.5-5 分散型WWWロボットの構成
予備実験では、7カ所(早稲田大学、慶応大学、京都大学、北陸先端科学技術大学院大学、大阪府立大学、シャープ、電子技術総合研究所)にPRSを設置し、103のWWWサーバを対象にデータ収集を行った。データ収集は、インターネットに与える影響を小さくするために午前2時〜午前8時の間にPRS3を動作させた。
3 各PRSでは100スレッドを同時起動し異なる100個のWWWサーバに対して同時にアクセスを行った。
図3.5-6に、各PRSが個別に収集した場合(個別収集)、担当WWWサーバを負荷均等化アルゴリズムにより負荷を均等化させた場合(分散収集)、さらに負荷均等化アルゴリズムを使った場合の収集時間予測値(均等化予測値)、の3つの場合における収集時間(コスト)を示す。図に示すように、負荷均等化を行った分散収集を行うことで、7分散時に5.5倍(慶応大学による単独収集を基準とした場合)〜22倍(電総研での単独収集を基準とした場合)の速度向上が得られた。
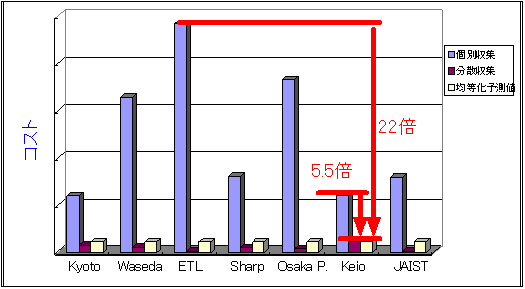
図3.5-6 収集時間の比較(7分散時)
一方、図3.5-7に示すように、負荷均等化アルゴリズムにより負荷を均等化させた場合の予測収集時間(コスト)と、実測値の間には85%程度の誤差が観測された。原因として考えられるのは①負荷均等化を行う際に用いたPRS〜WWWサーバ間のデータ転送速度の値が祝前日の深夜の値を使った点と、②ネットワークあるいはWWWサーバの負荷の変動による点の2点である。前者については、さらに別の平日に収集実験を行うことにより、仮定が正しいことを検証した。すなわち、同じ平日であれば、実測値と計算値との誤差を10%程度に小さくできることを確認した。後者については、PRS側のログを解析することにより、特定のWWWサーバに対して予測値と実測値が大きく異なる場合(最大10倍程度)があることが判明した。ただし、この原因が、ネットワークあるいはWWWサーバの何れにあるかについては現段階では特定できていない。
2000年2月現在で、30ヵ所にPRSを増やしjpドメイン内の全WWWサーバを対象に収集実験を継続しており、2000年4月から実運用に入る予定である。実験に関する詳細は、http://www.etl.go.jp/~yamana/DWR/ から手に入れることができる。
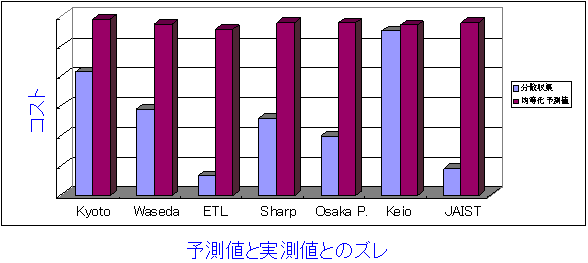
図3.5-7 予測値と実測値とのズレ
3.5.5 世界における分散型WWWロボットの研究状況
1)Harvest[5]
Harvest(図3.5-8)は、インターネットの将来や現状に関して技術的側面から研究を行う団体であるIRTF(Internet Research Task Force)(http://www.isi.edu/irtf/irtf.html)の研究グループ(IRTF-RD)が中心となって、ARPA(Advanced Research Projects Agency(現DARPA))やNSF(National Science Foundation)のサポートを受け、1993年〜1996年に行われた研究である。Harvestでは、Gathererと呼ぶWebロボットをネットワーク上の複数カ所に配置し分散収集をすることができる。また、Brokerと呼ばれるインタフェースを用いることにより、複数のGathererが収集したデータに対する検索を実現している。しかし、Harvestでは、Gathererを各WWWサーバ上に(あるいは同一ドメイン内に)配置し、ネットワーク上の負荷を軽減することを想定しているために、分散収集時のWWWサーバ割り当てに関する研究は行われなかった。このため、Gathererが受け持つWWWサーバ群は、静的にURLで指定することしかできず、分散を自動で行うための仕組みを持っていない点が残念である。なお、Harvestで開発された技術は、Netscapeのカタログサーバーに利用されている。
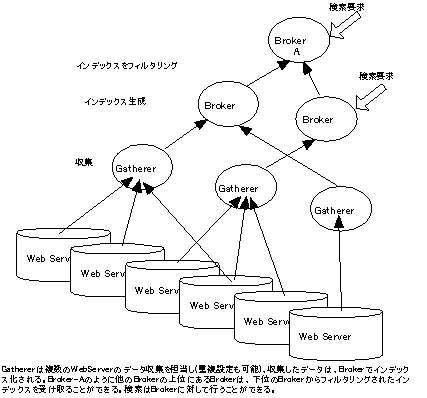
図3.5-8 Harvest
2)WebAnts[6]
WebAntsは、Texas Instrumentsからの資金を受け、1994年〜1995年にJohn.R.R.Leavitt氏(現在Lycos)を中心にカーネギーメロン大学で行われたプロジェクトである。WebAntsは、複数のエージェント(Ant=蟻と呼んでいる)が協調してWWWサーバ群に対して索引付け(Indexing)と検索を行う機能を提供する。索引付けでは、各Slave AntがMaster Antに対して対象となるWebページを収集してよいかどうかを尋ねる。Master Antは、他のSlave Antで収集していなければ、「収集開始の指示」を出すが、既に他のSlave Antで収集していれば「収集不要の指示」を出す。また、Master Ant間では、どのWebページが収集されているかという情報を共有している。このような仕組みによって、Webページを分散収集する際の重複を避け、効率的な収集が可能となる。WebAntsの具体的な性能についての報告が無いため、性能評価できないが、1996年5月に検索サービスサイトのLycosに採用されて現在に至っている。
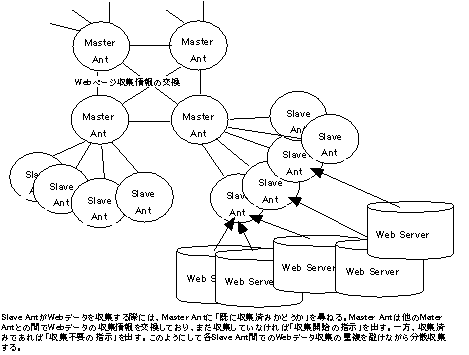
図3.5-9 WebAnts
3.5.6 Webデータ収集の今後の方向性
WWWサーバ数は毎年ほぼ倍々で増加し続けており、今後もこの傾向が続くと考えられる。このようなWWWサーバの増加に伴って、Webページも指数関数的に増大しており、2000年1月現在では、約17.8億ページと予測される。このようなWWW空間の巨大データに対する索引付けを行うためには、これまで述べてきたように、一カ所からだけではなく、インターネット上の複数カ所から協調してデータを収集するという新しいインフラ整備が必要になる。さらに、これまでのような「検索を1カ所で実現する」という考え方から、「検索自体も分散させる」という新しい発想と研究が重要となることは間違いないであろう。
参考文献