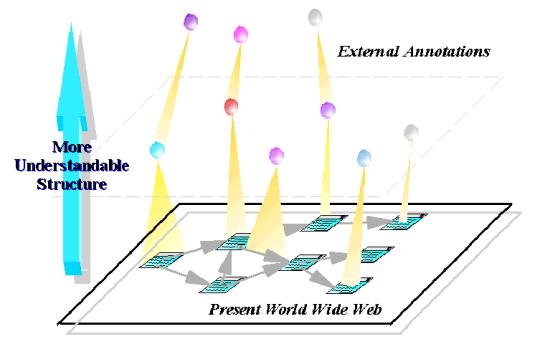
図3.3-1 WWW 上に構築される上位構造
本稿では、WWW上に、より上位の構造を構築する手法を紹介する。その上位構造はWeb の情報に新たな利用法と価値を与えるものである。具体的には、Webドキュメントの任意のエレメントにアノテーションと呼ばれる付加情報を付与する仕組みを導入し、そのドキュメントへのリクエストに対してアノテーションを考慮して加工した結果を返すプロキシーを実現した。この場合のコンテンツ加工(一般にトランスコーディングと呼ばれる)は、アノテーションに基づくドキュメントの意味的内容を考慮したものなのでセマンティック・トランスコーディングと呼ばれる。アノテーションには、大きく分けて、文章の言語構造を付与する言語的アノテーション、イメージやリンクなどのエレメントに対するコメントアノテーション、ビデオなどのマルチメディアデータの意味的構造に関するマルチメディアアノテーションがある。コメントアノテーションには文章の他にリンクやイメージを含めることもでき、文章の場合はやはりその言語構造がXML 形式のタグとして埋め込まれている。セマンティック・トランスコーディングの具体例として、ビデオや音声などのマルチメディアデータを含むドキュメントの要約、翻訳、音声化、視覚化などがある。また、アノテーションのその他の利用法には、自然言語による内容検索や、関連するコンテンツの検索と要約、さらに知識発見がある。
3.3.1 はじめに
WWW(World Wide Web, 以下Web)のようなオンラインドキュメントの作成と公開あるいは共有化のシステムは、新しいスタイルのドキュメントのあり方を示したという点において革新的だと言える。しかしながら、それらのドキュメントの内容を機械的に処理することは依然として非常に困難である。その理由としては以下の点が挙げられる。
つまり、Web は自由度の高いメディアであることは疑いないが、読者にとって必ずしも親切になっていないばかりか、深い内容の機械的な処理に適しているわけでもない、と考えられる。
そこで、われわれは、機械的な処理を前提としたドキュメントの再利用を支援する仕組みを開発し、それに基づくさまざまな応用例を実現し、将来的には、Webをさらに拡張した、ドキュメント利用の統合的プラットフォームを広く一般に普及させることを考えている。
その最初のステップとして、原著者を含む多くの人間がドキュメントの内容に関する補足的情報を付加できるような枠組み、および、その情報を加味して、ドキュメントを読者に適した形に加工する仕組みを開発している。
3.3.1.1 Web上のさらなる構造
従来のWebは一枚の平面上に存在するグラフとして捉えることができる。われわれは、Web を平面から立体に拡張する手法を提案する。それは、外部アノテーション(各々のコンテンツの外部に存在するアノテーション)によって実現できる。
図3.3-1 WWW 上に構築される上位構造
図3.3-1はわれわれのイメージするWeb の上位構造を表している。
Webの上位構造とは、コンテンツに対するメタコンテンツ、さらにそのメタコンテンツに対するメタコンテンツという具合に、Web をより立体的に捉える構造である。ここでは、そのようなメタコンテンツを外部アノテーション(以下では、単にアノテーションと表記する)として一般化する。よく知られているアノテーションの例は、外部リンクである。これは、XML(eXtensibleMarkup
Language)の仕様の中で議論されていることであるが、まだ実装されていないこともあり、現在のWeb のアーキテクチャの上でどのように実現されるのかわかっていない[16]。アノテーションのその他のよくある例は、コンテンツに対するコメントや評価などの、著者以外の人による、そのコンテンツの読者に対するメッセージである。
これはもちろん無制限に許可することはできないかも知れないが、コンテンツを理解する上での重要な手がかりになる。たとえば、視覚障害のある人にとって、内容記述のないイメージは理解不能であるが、第三者が付けたコメントを読み上げることによって、イメージの理解が可能になる場合がある。
アノテーションを作成し、公開することが容易になれば、Web の表現力は大きく拡張され、その利用価値は飛躍的に向上するものと思われる。
3.3.1.2 コンテンツ適応
アノテーションは、コンテンツの表現力を向上すると同時に、その利用法において重要な役割を果たす。その一つが、コンテンツ適応(コンテンツをユーザーの都合に合わせてカスタマイズすること)である。一般に、テキストを他の言語に翻訳するとか、適切な量に要約するとか、音声で読み上げるなど、コンテンツを加工して提示することをトランスコーディングと呼んで、盛んに研究が行われている。あるいは、コンテンツの配信の途中で、イメージの解像度を低くしたり、サイズを縮小するなどして、サーバーからバンド幅の狭いクライアントへの伝達効率を上げようとするのもトランスコーディングの一種である[3]。したがって、コンテンツ適応とは、ユーザーの使用するデバイスやネットワークの環境、さらに個人のプロファイルなどのコンテキストを考慮してトランスコーディングを行なうことであると言える。しかし、柔軟なトランスコーディングはより深いコンテンツの解析を必要とし、解析が失敗すれば、その結果として生成されるものはオリジナルのコンテンツの理解をさまたげるものになってしまう。われわれは、アノテーションがコンテンツの内容理解を促進するものと位置付け、それを利用したトランスコーディングの枠組みを実現した。それをセマンティック・トランスコーディングと呼ぶ[8]。
セマンティック・トランスコーディングは、基本的にテキストコンテンツの処理を中心としたものであるが、その手法はビデオやイメージなどの非テキストコンテンツの加工にも応用され、マルチメディアデータを含む一般的なドキュメントに適用できる。
セマンティック・トランスコーディングのシステム構成は図3.3-2のようになる。
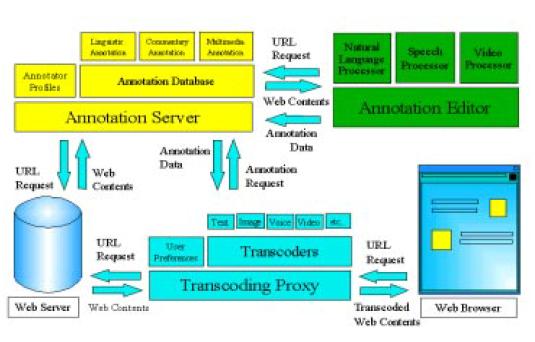
図3.3-2 セマンティック・トランスコーディングの構成
3.3.1.3 知識発見
コンテンツ適応以外のアノテーションの利用法として知識発見がある。これは、アノテーションを含む大量のWebコンテンツから、機械的に何らかの発見をさせようとするものである。従来の検索エンジンのように、キーワードから複数のWeb
ページを検索するのではなく、ユーザーのある要求を満たすような情報を複数のコンテンツを合成して作り出すのである。たとえば、IBMの製品に関する一年分のWeb
情報から、IBM のその一年の製品戦略に関するサマリーを生成する、ということが実現できる。
現在のところ、アノテーションに基づいて、内容的に類似するコンテンツを収集し、それぞれのサマリーを含む一つのドキュメントを生成する程度のことが可能になっている。知識発見に関しては、まだまだ多くの研究が必要であるが、アノテーションによって大きく促進されることは間違いがない。
3.3.2 アノテーション
アノテーションは、コンテンツに対するメタコンテンツであり、XML 形式のデータとして表現される。もちろん、アノテーションに対するアノテーションも考えられるが、これはまだ実現されていない。われわれは任意のHTML
ドキュメントの任意のエレメントにアノテーションのXML データを関連付ける仕組みを開発した。具体的には、XPointer を用いてHTMLエレメントを指定し、アノテーションデータのファイル名を関連付けるテーブルを用意する。
この場合のアノテーションは大きく分けて3種類に分類される。一つは、テキストに言語的情報を付与するもので、言語的アノテーションと呼ばれる。二つ目は、ドキュメント内の任意のエレメントに注釈を付けるもので、コメントアノテーションと呼ぶ。三つ目は、ビデオなどのマルチメディアデータにその内容に関する構造を付与するもので、マルチメディアアノテーションと呼ばれる。
3.3.2.1 アノテーションの作成と管理
アノテーションの作成と管理のために、われわれはクライアントサイドのアノテーションエディターとアノテーションサーバーを開発した。
アノテーション環境は図3.3-3のようになっている。
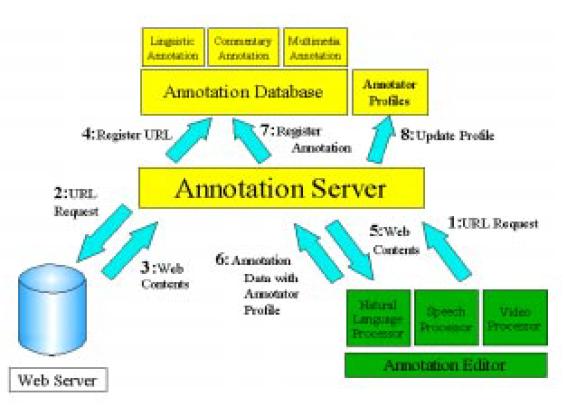
図3.3-3 アノテーション環境
たとえば、HTMLファイルの場合、次のようなプロセスでアノテーションが作成され、管理される。
3.3.2.2 アノテーションエディター
アノテーションエディターはJava アプリケーションとして実装されており、アノテーションサーバーと通信できるようになっている。
アノテーションエディターは以下の機能を持っている。
図3.3-4はアノテーションエディターとWeb ブラウザーの画面例である。
エディターの左側のウィンドウは、HTML ファイルの内部構造を示している。Web ブラウザー上で任意のHTML エレメントを選択すると、その部分のテキストがエディターに渡され、エディターの右側のウィンドウに表示される。選択された部分には自動的にXPointerと呼ばれるエレメントのIDが付与される。
このエディターを用いて、ユーザーは言語構造(構文や意味に関する構造)をテキストに関連付けたり、ドキュメント内の任意のエレメントにコメントを付けたりすることができる。言語構造は、まず自動的に生成されるが、その構造に曖昧さが含まれる場合は、それをインタラクティブに解消することができる。言語構造を修正するために、自動的に解析された構造をわかりやすく表示するための工夫を行なっている。
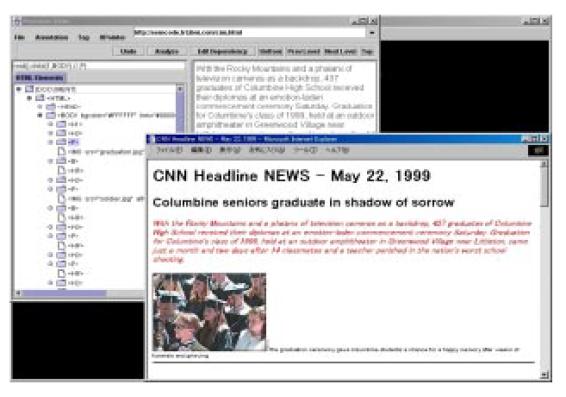
図3.3-4 アノテーションエディターの画面例
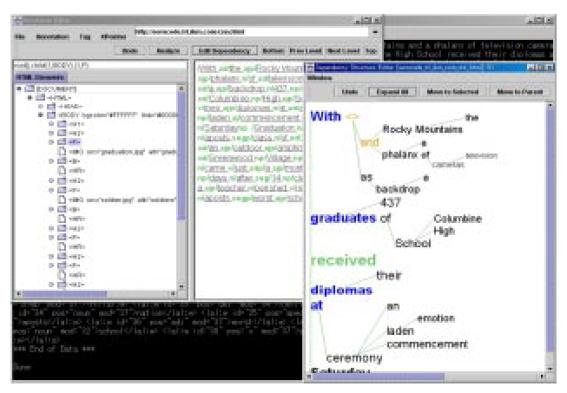
図3.3-5 言語的アノテーションの修正画面
言語的アノテーションは図3.3-5の右下に表示されている画面上の操作によって修正できる。
3.3.2.3 アノテーションサーバー
アノテーションサーバーは、任意のアノテーターからのアノテーションデータを受け付け、アノテーターごとに区別して保存する。また、アノテーションサーバーはアノテーションデータに含まれるURL
を調べて、URLの示すドキュメントのハッシュ値を覚えておく。これは、あとでトランスコーディングのときに、同じURLでリクエストされたドキュメントとアノテーションを作成したドキュメントの間の差分を検出するときに利用される。これにはDOM(Document
Object Model)ハッシュと呼ばれる手法が利用される[6]。これは、ハッシュ値を計算する対象を文字列ではなく、ドキュメントの内部構造に関して行なうもので、どのHTMLエレメントが更新されたかを知ることができる。
アノテーションサーバーはアノテーター、URL、XPointer、DOMハッシュ値のテーブルを作ってデータベースに登録する。後で説明するように、トランスコーディングプロキシーがアノテーションサーバーにリクエストをするときに、URLが送られた場合は、そのURLに関するアノテーションデータ(アノテーターの名前とXPointer、そして言語的あるいはコメントアノテーションを含むファイル)が返される。もし、アノテーター名でリクエストされた場合は、そのアノテーターによるすべてのアノテーションデータが返される。
さらに、われわれはドキュメントの原著者がアノテーションを制御する方法を開発している。原著者が自分のドキュメントに対する一切のアノテーションを許可しない場合、ドキュメント内にアノテーションを許可しないという記述を入れることによって、アノテーションサーバーがそれを認識し、アノテーションエディターからの要求がきても拒否するような仕組みになっている。
3.3.2.4 言語的アノテーション
言語的アノテーションは、ドキュメント内テキストエレメント(<H%>,<P>,<OL>,<UL>,<DL> など)の文章の意味構造に関するアノテーションである。それは、語間の係り受け、代名詞の指示対象、多義語の意味など、かなり細かい情報を含む。このタイプのアノテーションは、ドキュメントの内容理解に大きく貢献し、テキストのトランスコーディング以外にも、たとえば、内容検索や知識発見などに利用される。
言語的アノテーションは、具体的にはXML 形式のタグファイルである。タグセットには、電総研の橋田らの提唱するGDA(Global Document Annotation)[2]のものを用いている。GDA
は多言語間に共通な意味的・語用論的タグをドキュメントに付与することにより、その機械的な内容理解を可能にし、ドキュメントの検索・要約・翻訳を実用的なレベルで実現するとともに、ドキュメントの作成・公開(
共有化) ・再利用を考慮した統合的なプラットフォームを構築して、世界的に普及させようという、壮大なプロジェクトである。われわれのセマンティック・トランスコーディング・プロジェクトはGDA
を現在のWeb のアーキテクチャ上で利用可能にし、さまざまなサービスと連動させることによって、GDA の思想をより具体的な形で浸透させようとする試みの一つと位置付けられる。
GDAでは以下のことを目的としている。
うまいタグの標準を作って普及させれば、機械にも人間にも理解可能な知識ベースが世界規模で自己増殖し、自然言語処理やAIの技術が爆発的に実用化されて一般ユーザーが恩恵を受けるのみならず、研究コミュニティにとっては基礎研究のための大量かつ良質のデータが手に入るだろう。意味や常識があと100年ぐらいは機械でまともに扱えないとすれば、そんな機械でもそれなりに活躍できる環境を整えてやる必要がある。GDAはその環境を整えることにより社会的ニーズに答えながら基礎研究をも進展させようという計画である。
GDA タグ付きドキュメントは、たとえば以下のようなものである。
<su><adp rel="loc"><adp rel="pos"> 人間の</adp><np sense="0f2e4c"> 細胞</np> には、</adp><np syn="p"><np><vp><adp><adp><npsense="0f74e9"> 自動車</np> でいえば</adp><adp rel="iob"> アクセルに</adp> 当たり、</adp><adp rel="obj"><np id="a1" sense="3be2c7"> がん</np> を</adp><adp rel="gra">どんどん</adp> 増殖する</vp><n> 「<namepid="a2"><np eq="a1" sense="3be2c7"> がん</np><n id="a3" sense="3bf4d0"> 遺伝子</n></namep> 」</n></np> と、<np><adp><np rel="pos" sense="107ab3"> ブレーキ</np> 役の</adp><n> 「<namep id="a4"><np eq="a1"rel="obj" sense="3be2c7"> がん</np><nsense="10d244 3cf57c"> 抑制</n><n eq="a3"sense="3bf4d0"> 遺伝子</n></namep> 」</n>6.</np></np> がある。</su><su><adp rel="cnd"><adp rel="sbj"><np><adp rel="pos"><np eq="a2 a4" sense="0face2"> 双方</np> の</adp> バランス</np>が</adp> 取れていれば</adp> 問題はない。</su>
これらは統語構造を表わしており、各エレメント( タグで囲まれた部分) は統語的構成素である。ここで、<su> は一文の範囲を表し、<n>, <np>, <vp>,<adp>, <namep> は、それぞれ名詞、名詞句、動詞句、形容詞句/ 形容動詞句( 前置詞句、後置詞句を含む) 、固有名詞句を表す。syn="p" は等位構造( たとえば上の「〜がん遺伝子と〜がん抑制遺伝子」) を表わす。等位構造の定義は、係り受け関係を共有するということである。特に何も指定がない場合は、たとえば、<np><adp rel="x">A</adp><n>B</n> </np> はA がB に依存関係があることを表す。また、rel="x" は<adp>エレメントの関係属性を表している。また、sense="*"は語義属性を表している( 属性値としては、たとえばEDR 単語辞書[5] の概念識別子が利用できる。また、一語が複数の語義を持つ場合は、属性値が複数になる) 。 一般にGDAドキュメントの構造は図3.3-6のようになる。
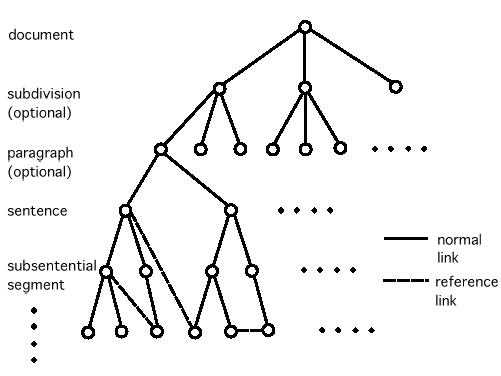
図3.3-6 GDAドキュメントの構造
つまり、GDA ドキュメントはネットワーク構造を成しており、そのリンクには、タグの入れ子構造よって定義される関係と参照関係の2種類がある。
また、GDAのタグ集合は10項目以上からなるが、さしあたり、そのうちで自動タグ付け作業が比較的大変だと思われる、統語構造、文法・意味関係、語義、照応、修辞関係という5
項目だけを扱っている。GDAタグセットの詳細については、http://www.etl.go.jp/etl/nl/gda/を参照のこと。
文法機能(主語、目的語、間接目的語)、主題役割(動作主、被動作者、受益者など)、および修辞関係(理由、結果など)は関係属性によって表示する。関係属性はrel="*"
という形で表される。主語、目的語、および間接目的語の主題役割の判断は難しいことが多いので、文法機能(sbj 、obj 、iob)を用いる。
属性の内、id="*" はID 属性を示す。ID 属性はそのエレメントのユニークな識別子である。また、先行詞のID 属性の値を照応詞のeq 属性の値にすることにより、照応(anaphora)
や共参照(coreference)を表示する。たとえば、上の例で、「双方のバランスが取れていれば問題はない。」の「双方」は「がん遺伝子」と「がん抑制遺伝子」を指し示すことが、属性eq="a2
a4" によって表示されている。
照応詞がいわゆるゼロ代名詞(省略)の場合には、関係属性の値を属性名として用い、値を先行詞のID 属性の値とする。いわゆる必須格(主語、目的語、間接目的語など、述語が表現する事象の内部構造を記述する補語)に相当するゼロ代名詞は必ず補うようにする。手段や理由などの任意格要素は補わなくても構わない。
このようなタグ付けは多くの労力を要すると思われるが、アノテーションエディターにいくつかの自然言語処理モジュール(統語・意味解析、照応解析など)を統合することによって、極力人間の負担を減らせるように工夫している。人間がインタラクティブに解析した部分は、事例として次の機会に再利用されるので、それによって解析の精度が少しづつ上がっていくことになる。解析の精度が上がれば、それだけ人間の負担が減ると思われるので、将来的にはタグ付けのコストは十分に少なくなるだろう。
言語的アノテーションは今のところ自動要約と翻訳および音声合成に使われている。最も単純で有効な例は、固有名詞や専門用語に関するもので、これらの意味や読みがアノテートされていれば、その理解や音声読み上げに大いに役に立つ。また、言語的アノテーションによって機械翻訳の精度を飛躍的に向上させることも可能である。
3.3.2.5 コメントアノテーション
主に非テキストエレメント(<IMG>、<TABLE> など)に対する任意のコメントを含むアノテーションである。コメントは文章だけでなく、イメージやリンクなども含むことができる。コメント文はやはりGDA
による統語・意味構造に関するタグを含んでいる。このタイプのアノテーションはトランスコーディングの結果、ドキュメント上にポップアップする形で表示される。
図3.3-7はWeb ドキュメント上にコメントをポップアップした様子を表している。 たとえば、イメージにその内容を記述した文章をアノテーションとして関連付けた場合、ドキュメントを音声化して提示するときに、コメントの部分を読み上げることによって、視覚障害者によるイメージの内容理解に貢献することができる。その他にも、コメントアノテーションを利用することによって、非テキストコンテンツの検索を容易にすることができる。
もちろん、コメントアノテーションはテキストエレメントにも付与することができる。たとえば、単語のスペルミスや誤字脱字が含まれるコンテンツに対して、該当する部分に、正確なスペルなどを含む情報を補足することができる。ただし、テキストに対するコメントは言語的アノテーションに含まれる形で記述することもできる。この種のアノテーションはトランスコーディングのときに補足された情報でオリジナルのテキストを置き換えることにも利用できる。
さらに、ハイパーリンクに対してコメントを加えることもできる。これは、リンクをたどる前にリンク先の情報を簡単に紹介するという役割を果たすことができる。もしリンク先のコンテンツに言語的アノテーションが存在すれば、その要約を作成して注釈とすることによって、各リンクに自動的にアノテーションを付けることが可能になる。
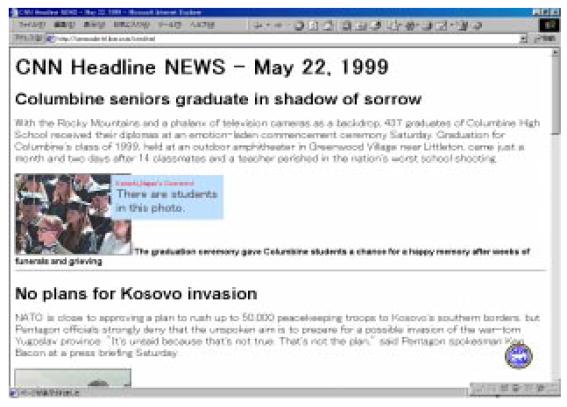
図3.3-7 コメントのポップアップ
コメントアノテーションは以前から研究が行なわれている。それは、ドキュメントを共有するグループが、ドキュメントに関する補足情報を効果的に共有するために、コメントを管理するサーバーと、ドキュメントにコメントを加えて加工するプロキシーを用意するというものである[10, 11] 。基本的には、われわれの枠組みもこれと同様である。ただし、コメントを付与する単位がドキュメント全体ではなく、任意のHTML エレメントに対して行なえるようになっている。また、われわれの枠組みにおいてコメントはそれを読む人間のためというより、そのドキュメントを機械が理解して適切にトランスコードするための手段として捉えている。
3.3.2.6 マルチメディアアノテーション
われわれのアノテーション手法はビデオなどのマルチメディアデータにも適用できる。ビデオは今後インターネットの主要な情報リソースになっていくと思われる。それは、テレビが新聞よりも多くのアテンションを集められるように、動画像の持つ魅力はテキストやイメージの持つそれよりも一般に大きいからである。さらに、最近はテレビをハードディスクに録画したり、ビデオカメラがテープではなくディスクに映像を記録できるようになってきたため、ディジタル化された映像を容易に作成・入手できるようになってきたためである。このようにオンライン情報におけるビデオの割合が増えるにしたがって、それを検索したり、要約したりする技術の必要性が高まってくるのは明らかである。
われわれはビデオの内容を表すテキストを自動的に生成して、半自動的にビデオアノテーションを作成するシステムを開発した。このシステムは同時にビデオのシーンの変わり目を認識して、シーンに関するタグ付けを支援する。
図3.3-8はビデオアノテーションエディターの画面例である。
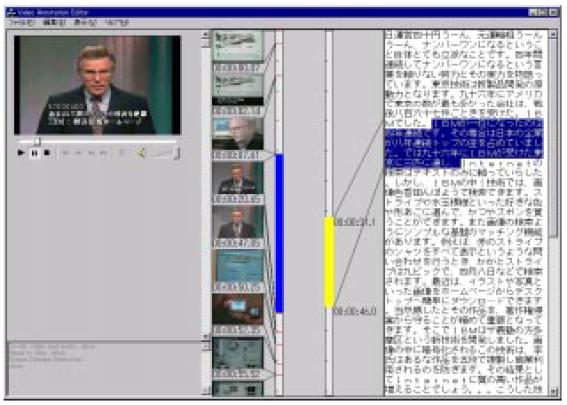
図3.3-8 ビデオアノテーションエディターの画面例
もちろん、ビデオに関してはこれ以外にもさまざまな試みがなされている。その一つが現在規格の策定が進められているMPEG-7 である[7] 。MPEG-7
はISO/IECに属するMoving Picture Experts Group(MPEG)によって標準化活動が行なわれている新しい規格で、マルチメディアコンテンツ記述という新しい仕様を含んでいる。このコンテンツ記述はわれわれのアノテーションと同様にビデオデータに直接含まれないデータ(
いわゆるメタデータ) によって検索や要約を容易にする仕組みを設けよう、ということである。さらに、ビデオを再生するデバイスのスペックに応じて、画像の解像度を変えたり、色情報を減らしたり、音声の帯域を制限したりすることも考慮されている。さらに、オブジェクトレベルの記述というのがあり、シーンに登場する人物や物や場所などの情報も付け加えることが可能になるそうである。ただし、参加しているさまざまな企業の思惑が密接に関わってくるので(標準化活動というのはどれもだいたいそうであるが)、仕様が確定するにはまだ多くの時間を必要とし、実際に利用可能になるのはずいぶん先の話になりそうである。
MPEG-7の仕様が固まるのを待ってから作業を始めるのでは遅いので、われわれはまずさまざまな試みを行なって、タイミングを見てMPEG-7 の規格と統合するつもりである。
われわれのビデオアノテーションは、自動的にシーンの検出を行ない、それらのシーンとやはり自動的に生成されたテキストの関連付けを行なって、さらに人や物などのフレーム内のオブジェクトに名前を付けていく、という形で行なわれる。それぞれのプロセスでは、ユーザー(アノテーター)が自由に介入して、インタラクティブに変更・修正が行なわれる。ビデオへのアノテーションは、いわゆるビデオの編集に比べて複雑な情報処理を含むため、人間の行なう部分も多少複雑になるが、自動処理の精度も徐々に上がっていくと思われるので、将来は編集ではなくアノテーションによってビデオを再利用する形式が一般的になると思われる。
3.3.3 セマンティック・トランスコーディング
セマンティック・トランスコーディングは前節で述べたアノテーションを用いたトランスコーディングであり、ユーザー情報を用いたコンテンツ適応の機能を有する。まず、基本的なメカニズムを紹介する。
トランスコーディングを行なう複数のモジュール(トランスコーダーと呼ばれる)は、HTTP(Hyper Text Transfer Protocol)プロキシー上で機能するプラグインとして実装されている。トランスコーダーを制御するHTTP
プロキシーをトランスコーディングプロキシーと呼ぶ。
図3.3-9はこのプロキシーを含むトランスコーディング環境を表している。トランスコーディングにおける情報の流れは次のようになる。
1.トランスコーディングプロキシーはクライアントのWeb ブラウザーからURL とクライアントIDを受け取る。
2.プロキシーはWeb サーバーにURLの示すドキュメントをリクエストする。
3.プロキシーはドキュメントを受け取ると、そのハッシュ値を計算する。
4.プロキシーは同時にアノテーションサーバーにURL に関連するアノテーションデータを要求する。
5.もしアノテーションデータが見つかったら、アノテーションサーバーはそのデータをプロキシーに送信する。
6.プロキシーはデータを受け取ると、それに含まれるハッシュ値と先ほど計算した値とを比較する。
7.同時にプロキシーはクライアントID に基づいてユーザー情報を検索する。ユーザー情報が見つからない場合は、ユーザーから与えられるまでデフォルトのセッティングを用いる。
8.ハッシュ値が照合したら、アノテーションデータとユーザー情報に基づいて適切なトランスコーダーを起動して、トランスコーディングを実行する。
9.プロキシーは加工されたコンテンツをユーザーのWeb ブラウザーに送信する。
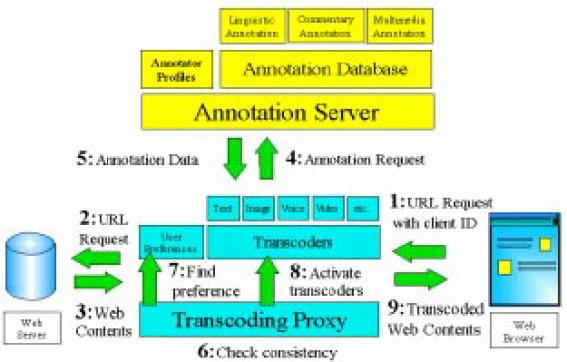
図3.3-9 トランスコーディング環境
以下で、トランスコーディングプロキシーと各種のトランスコーディングについて解説する。
3.3.3.1 トランスコーディングプロキシー
今回我々は、セマンティック・トランスコーディングを行うためのプロキシー実装環境として、IBM のWBI(Web Intermediaries)を使用した[4]
。これはIBMのWeb サイトalphaWorks からダウンロードできる(http://www.alphaworks.ibm.com/)。WBI は、プログラマブルなHTTPプロキシーであり、通常のプロキシーとしての機能の他に、ユーザー毎のアクセス制御や、プロキシーに流れるデータの加工を容易に行えるAPI(Application
Programming Interface)を提供する。
このWBIを利用したトランスコーディングプロキシーは、主要な機能として以下の3つを行う。
1. 個人情報の管理:我々は、ユーザーの特定にCookieを用いた。個人情報を管理するID を、Cookie データとしてユーザーに渡すことにより、ユーザーのアクセスポイントによらないユーザーの特定が行なえる。
しかし、既存のブラウザーは、Cookie をセットしたサーバーに対して、そのCookie を渡すものであり、プロキシーのCookie 利用は考えられていない。通常、プロキシーがユーザーを識別する方法は、ホスト名とIPアドレス(これらをクライアントID
と呼ぶ)によってのみである。
そこで、ユーザーが個人情報をセットした時に、Cookie 情報(ユーザーID)と個人情報を関連付け、一方、アクセスポイントの変化ごとにクライアントID
とCookie 情報(ユーザーID)を関連付け直すことでユーザーの特定を行なう。つまり、通常のプロキシーとして動くときは、クライアントID(ホスト名+IP
アドレス)→Cookie 情報(ユーザーID)→個人情報という流れで、クライアントID から個人情報を引き出し、アクセスポイントが変化したときは、プロキシーをサーバーとしてアクセスすることで、Cookie
情報を取得し、クライアントID とCookie 情報(ユーザーID)を関連付け直す。
2. アノテーションデータの収集と管理:トランスコーディングプロキシーは、アノテーションサーバーと通信して、アノテーションデータを入手する。アノテーションサーバーは複数存在するので、それぞれのサーバーの管理するアノテーションデータのインデックスを定期的に作っておき、ユーザーからリクエストがあったときに、どのアノテーションサーバーからデータを入手すべきかを判断するときに役立てている。
3. トランスコーダーの起動と結果の統合:そして、もちろん、プロキシーの最も重要な役割は、個人情報とアノテーションデータに基づいてコンテンツを加工することである。これは、必要なトランスコーダーを起動し、その結果を統合することによって行なわれる。
現在のところ、テキスト、イメージ、音声、ビデオのトランスコーダーが開発されている。これらのトランスコーダーは直列あるいは並列に結合され、複合的なトランスコーディングが実現される。たとえば、ドキュメントを要約後に翻訳して、さらに音声化するなどの一連の処理が、ユーザーの要求に従って実行される。
トランスコーディングプロキシーは、ユーザーからリクエストを受けるとアノテーションサーバーから適切なアノテーションデータを取得して利用する。このとき、ユーザーのプリファレンス情報(すでに登録されている場合もあるが、リクエストと共に送られてくる場合もある)にアノテーターが指定されている場合は、そのアノテーターのアノテーションを優先する。ただし、指定されたアノテーターのアノテーションが要求されたドキュメントに付与されていない場合は、他のアノテーターのアノテーションを使うこともある。もちろん、ユーザーはアノテーターの制限を付けないこともできる。その場合、コメントアノテーションはアノテーションサーバーにあるものをすべて付与することができる。ただし、言語的アノテーションはコンフリクトする場合があるので注意が必要である。現在では、コンフリクトした場合は、最初に見つかったアノテーションのみを使うことにしている。
3.3.3.2 テキストトランスコーディング
テキストトランスコーディングは言語的アノテーションを用いたテキストの加工である。現在のところ、テキスト要約と翻訳が実現されている。要約に関しては、筆者らが以前に発表したGDA
に基づく要約[9] の手法を用いている。
図3.3-10はWeb ドキュメントの要約例である。
一般に、要約には深い意味処理と多くの背景知識が必要である。しかし、これまでの研究の多くは表層的な手がかりやドキュメントの持つ何らかのスタイルに関するヒューリスティックスを用いるものであった。
たとえば、文の重要性を判断するのに使われる特徴素としては、文の長さ、キーワードの出現回数、時制、文のタイプ(たとえば、事実(〜である)、推測(〜だろう)、主張(〜べきだ)など)、修辞関係(たとえば、理由、例示など)、文頭からの位置、文末からの位置などがある。これらの大部分は、特に深い処理を行なわなくても、ある程度抽出できるものであり、それゆえ、これに基づく処理は非常にロバストである。
また、これまでの要約システム(たとえば、渡辺のもの[14])は、上記の特徴に基づいて計算された文の重要性の高いものを順に選択し、元の文章における文の出現順に並べるという手法を用いているものが多い。
確かに、これらは現在の技術をもって実用的なシステムを作ることに成功している。しかしながら、どれほどのヒューリスティックスをもってしても、要約の品質の向上はすぐに限界にきてしまうだろう。いずれにしても、内容に基づく処理は必須であろう。
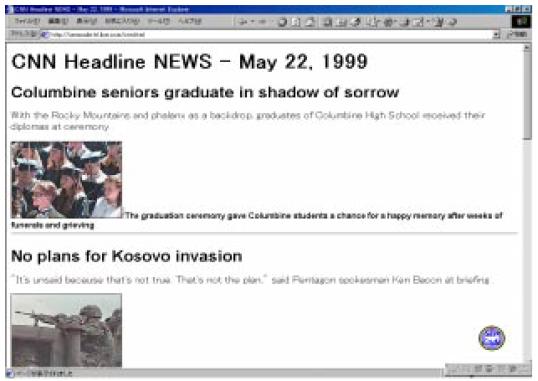
図3.3-10 Web ドキュメントの要約例
ここでは、GDA タグから得られる、文の構成要素の重要度(活性値)を用いた要約を提案する。この手法は、ドキュメントのドメインやスタイルに関するヒューリスティックスを用いていないため、GDA
タグの付いたものならどのようなドキュメントにも適用可能であり、また、文より細かい単位で重要度を計算しているので、一文をさらに短くすることも可能である。
要約のアルゴリズムは以下のようになっている。
現在のところ、単語の語義属性と一部の関係属性以外の意味表現に関するタグが決まっていないため、意味表現からの文生成は行なっていない。将来は、そのようなことも可能になり、読者の要求に従ってパラフレーズなどを行なうこともできるようになるだろう。
また、要約はそれを行なう人間の知識によっても変わってくるが、それを読む人間の興味などによっても変わってくるべきであろう。システムの情報処理を特定の個人に適応させることをパーソナライゼーション(
個人化) という。GDA タグを用いた要約は、内容に基づく一般的な手法によるものなので、個人の興味や嗜好のようなパーソナライゼーションのための情報を取り入れれば、その個人に特化した要約を行なうことができる。つまり、読み手が知りたい内容を含むように要約を生成することができるのである。
そのための手段として、以下のことを実現している。
テキストトランスコーディングのその他の例は言語翻訳である。現在、英語と日本語間の翻訳システムをトランスコーダーとして実現するプロジェクトが進行中である。さらに多くの言語の翻訳システムがトランスコーダーとして実現され、われわれのシステムに統合される予定である。近い将来、Web
コンテンツを母国語でしか表現していない人々が、トランスコーディングによってさまざまな言語圏の人々に情報発信できるようになる。
図3.3-11はWeb ドキュメントの翻訳例である。英日翻訳においては、日本アイ・ビー・エムが開発・販売している「翻訳の王様」の翻訳エンジンをアノテーションを考慮するように拡張したものを用いている。翻訳で用いる言語的アノテーションはIBM
東京基礎研究所の渡辺の設計によるもので、LAL(Linguistic AnnotationLanguage)と呼ばれている[15]。翻訳トランスコーディングでは、アノテーションデータをGDA
からLAL へ自動的にコンバートしてから翻訳エンジンに渡している。
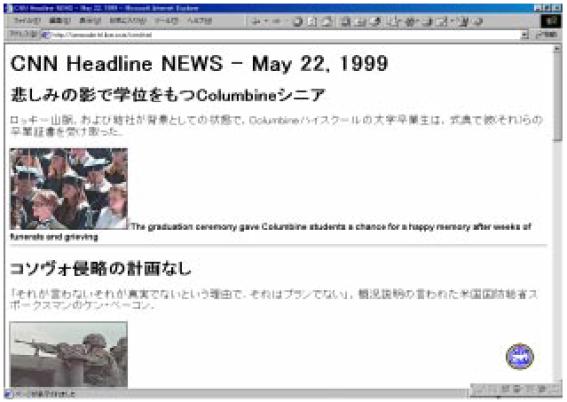
図3.3-11 Webドキュメントの翻訳例
3.3.3.3 イメージトランスコーディング
イメージトランスコーディングはユーザーの使用するデバイスなどの環境に合わせてドキュメントに含まれる画像のサイズや解像度を変化させる処理である。変換されたイメージは必ずオリジナルイメージへのリンクを含むようにしている。そのため、元のサイズや解像度で見たいときは、単にその画像をクリックすれば良い(ただし、元の画像がすでにリンクを含んでいるときはこの限りではない)。
イメージトランスコーディングはテキストトランスコーディングの要約と併用して、コンテンツの表示面積を縮小してユーザーの用いるデバイスの画面サイズに適合させることができる。
図3.3-12はイメージを縮小した例である。右下のウィンドウは設定を変更するためのもので、要約の分量やアノテーターの指定などもここで設定できる。
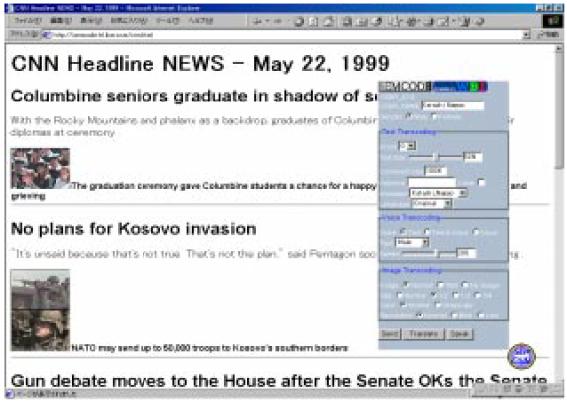
図3.3-12 イメージトランスコーディングの例と設定ウィンドウ
3.3.3.4 音声トランスコーディング
音声トランスコーディングとは、コンテンツを音声化するトランスコーディングである。これには2種類のやり方が考えられる。一つはトランスコーディングプロキシーが音声データを作成して配信するやり方で、クライアントが音声合成機能を持たない場合に有効である。たとえば、携帯電話からWeb
をアクセスするときに使えるだろう。最近はMP3(MPEG-1 Audio Layer3)のデコーダーが内蔵された携帯電話が発売されるようになったので、音声トランスコーディングはますます盛んになるであろう。
もう一つの音声トランスコーディングは、クライアントが音声合成システムを利用していることを前提に、音声合成に適したドキュメントに加工して配信するやり方である。前者は後者によって生成されたドキュメントをプロキシー側で音声合成を行なった結果と考えられるので、どちらのやり方もほぼ同じプロセスを必要とする。
音声合成に適したドキュメントは、イメージに対するコメントアノテーションを利用してイメージ部分の説明をテキストとして含んだり、固有名詞など辞書にない語を正しく読むために言語的アノテーションによる語の読み情報を含むことができる。また、読み上げ時に適切にポーズを置くために、正しいフレーズの切れ目に関する情報を用いることもできる。
図3.3-13は音声トランスコーディングを行なったドキュメントの例である。アノテーションを含む部分の最後にスピーカアイコンが挿入されている。これをクリックするとその部分の音声が再生される。
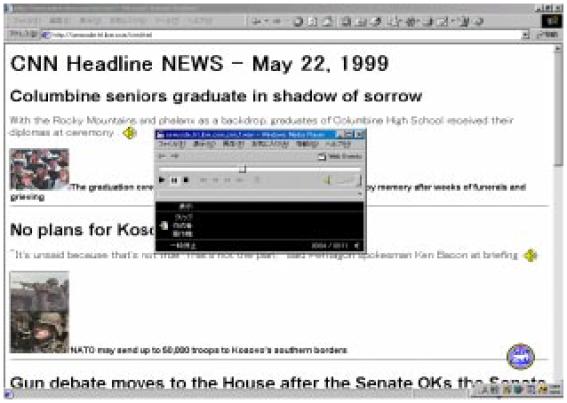
図3.3-13 音声トランスコーディングの例
3.3.3.5 ビデオトランスコーディング
ビデオトランスコーディングには、ビデオの要約、ビデオからテキストとイメージの集合への変換、ビデオの翻訳、ビデオからテキストのみへの変換などが含まれる。それらについて簡単に説明する。
ビデオの要約は、まずビデオのトランスクリプトを要約して、その要約に対応するビデオシーンを抽出することによって行われる。これは、トランスクリプトが対応する音声の出現するタイムコードを含んでいるため、そのタイムコードを含むシーンを選択することで要約できる。
図3.3-14は要約機能付きのビデオプレイヤーの画面例である。ビデオ画面の下にあるスライダーバーの濃い色の部分が要約に相当する。また、右のウィンドウには、シーンのタグ構造と、要約に含まれるシーン(チェックされているもの)が表示されている。
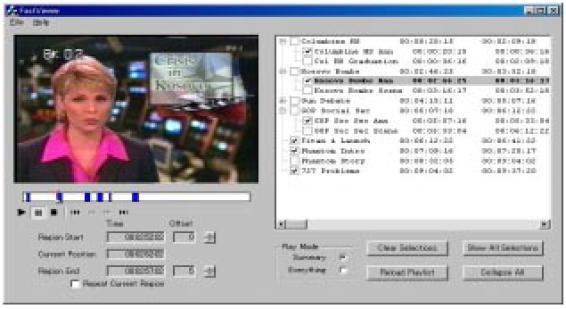
ビデオからテキストとイメージへの変換は、もう一つの種類のビデオトランスコーディングである。もし、クライアントのデバイスがビデオを再生することができない場合、ユーザーはビデオのコンテンツにまったくアクセスできなくなってしまう。その場合、ビデオトランスコーダーはそれぞれのシーンを代表するイメージとそれぞれのシーンの内容を表すテキストを含めたドキュメントを作成してユーザーに提示することができる。また、生成されたドキュメントをテキストトランスコーダーを用いて要約あるいは翻訳することもできる。
ビデオの翻訳は、テキストおよび音声トランスコーディングとの組み合わせで行なわれる。まず、トランスクリプトを翻訳し、その結果を音声合成に適した形に変換する。ビデオの再生と音声合成を同期させることによって、他の言語のビデオを作成することができる。この部分は、まだ実現されていないが、近い将来にわれわれのビデオプレイヤーに統合される予定である。
ビデオの要約はテキストの要約と同様に盛んに研究されている。古くはCMU のInfomedia があり、ビデオに含まれるさまざまな属性を自動抽出して、より重要な部分を選択している[13]
。たとえば、ビデオに現れる文字情報、人の顔、シーンの変わり目、クローズドキャプションと呼ばれる字幕情報などを利用して、あらかじめリストアップされた重要な固有名詞の出現頻度や、TF*IDF
法と呼ばれる情報検索の手法を用いてキーワードの重要度を計算し、そのキーワードの現れるシーンをつなぎ合わせて要約とする。
また、IBM アルマデン研究所のCueVideo はビデオのキーフレームを並べて表示して、人間がどれかを選択すると、その部分のビデオを再生することによって、人間がビデオ全体を見る手間を減らしている[1]
。また、音声のみを再生して、画像は静止画をシーンが変わるごとに変化させることによって、ダウンロードする情報の容量を少なくする工夫もなされている。このとき音声の再生スピードを変化させることによって、早口にしたり、ゆっくり聞き取りやすくすることもできる。CueVideo
はディスタンスラーニングと呼ばれる遠隔教育におけるビデオの利用に焦点を当てて研究が進められており、教育に使われるビデオを効果的に見せるためのさまざまな手段が開発されている。たとえば、ある講義のビデオとその講義の資料(PowerPoint
などのスライドファイル) を自動的にリンクして、再生時に連動させることもできる。また、ビデオのシーンを検索するのに、任意の単語やフレーズを入力すると、音声認識を利用してその言葉を含む部分を抽出してリストアップし、そのうちのどれかを選択するとその部分を再生する、という通常のテキスト検索と同様のことがビデオに対して行なえる。
同じくIBM ワトソン研究所の開発したVideoZoomは、ビデオの画像の解像度を動的に変化させ、荒い画像のビデオから徐々に鮮明にしていったり、荒い画像のビデオをまずダウンロードして、細かく見たいところのみについて差分の情報を追加していくことができる[12]
。これも、ネットワークやデバイスの制約に依存して、ビデオコンテンツを加工するトランスコーディングの一種と言える。
これらのビデオトランスコーディングはアノテーションを用いないので、一度実装すれば利用するのは簡単であるが、ビデオをさまざまな形で再利用するのには問題がある。われわれはビデオが今後重要な情報ソースになることを確信しているので、要約やフィルタリングに限定されない、さまざまな再利用を可能にする枠組みをできるだけ早めに用意しておきたいと考えている。また、将来MPEG-7
のようなアノテーションの標準的フレームワークが確立した場合にも、われわれの仕組みは容易にコンバートして利用可能である。
3.3.4 おわりに
われわれの次なるターゲットは大量なWeb コンテンツからの知識発見である。アノテーションはそれぞれのドキュメントから重要な部分を抽出するのに大いに役に立つ。また、たとえば、あるアノテーターがいくつかのドキュメントにコメントを付与しているとして、そのアノテーターがある分野のエキスパートであるとすると、機械は自動的にその人のアノテートしているドキュメントをかき集めて、それぞれの要約をまとめた一つのドキュメントを作成することができる。これは、ある特定の分野を概観するのに有益であると思われる。
マルチメディアデータを含むWeb コンテンツの効率的な検索もターゲットの一つである。この場合の検索の質問には単なるキーワードではなく、音声あるいはテキストの自然言語文を用いることができる。
近い将来に、人々はWeb から情報を得るために、検索エンジンを用いるのではなく、知識発見エンジンを用いて、ハイパーリンクを集めた大量のリストの代わりに、短時間で容易に理解できるように個人化された情報のサマリーを読むことができるようになるだろう。それは来るべき情報の洪水から自分自身を守る最良の方法になると思われる。しばらくは、多少の労力を人間に強いるかも知れないが、目標のために努力をしない人が充足感を得られることがないように、オンラインコンテンツを人類共有の知識とするために一丸となって努力をすることがなければ、人々は今後も無限に拡張していく情報の圧迫から自分自身を解放することができないだろう。
謝辞
セマンティック・トランスコーディング・プロジェクトは筆者と慶応大SFC の学生との共同研究である。参加者の細谷真吾氏、川喜田佑介氏、有賀征爾氏、白井良成氏に感謝します。また、ビデオアノテーションエディターの音声認識部については、IBM 東京基礎研究所の西村雅史氏と伊東伸秦氏、言語解析と翻訳トランスコーダーについては、同研究所の渡辺日出雄氏、アノテーションエディターのHTML 解析部については、同研究所の近藤豪氏、音声トランスコーダーについては、同研究所の鳥原信一氏に協力していただきました。さらに、言語的アノテーションに関しては、GDA プロジェクトと連携して行なわれています。プロジェクトリーダーの電総研の橋田浩一氏には、常に議論の相手をしていただいています。ここに記して感謝いたします。
参考文献