3.1.1 はじめに
ナレッジマネジメントとは、企業の営存 (経営・存在) の価値を高めるようなナレッジをナレッジワーカーが強力な情報技術の助けを借りながら、ナレッジを創造・共有・再利用するプロセスを高速化、効率化するマネジメントのことである。ナレッジマネジメントは一般に「人、組織文化、プロセス、技術、知識」の5つの視点から分析されることが多い。本節では、ナレッジマネジメントによる知識創造企業の実態を踏まえて、AI技術を含む情報技術がどのようにナレッジマネジメントに貢献できるか、北陸先端科学技術大学院大学(JAIST)での実践事例の紹介を含む21世紀知識産業を創出する情報技術ビジネス展開について提言する。最後に、日米の情報技術格差の根源に関する私見を披露して、今後のナレッジマネジメント格差解消の縁としたい。
3.1.2 ナレッジマネジメント
近年、知識に関する組織論と情報技術が融合し、知識の創造・共有・再利用に関する情報技術活用のあり方、技術開発の方向性に新たな展開が見られ、ナレッジマネジメント(1,7,8,12,13,14,19)
と称する一大研究領域が勃興してきた。ナレッジマネジメントは野中郁次郎の一連の著作(16,17,18)を端緒とし、トーマスH.ダペンポートの組織論研究(14)をベースとして、実践的情報技術が根づいている欧米を中心に進展してきた。
野中は名著「知識創造企業」(17)で、マイケル・ポライニの暗黙知の理論に着目し、形式知と暗黙知の知識変換プロセスを共同化、表出化、連結化、内面化という4つのプロセスからなるモデルを用いて、知識創造のプロセスを明らかにした。更にこのモデルと「場」、「知的資産」の三者をバランスさせ、活性化させる役割としての「知のリーダーシップ」(14)の重要性を喚起している。これに対して、ダペンポート(14)はナレッジマネジメントのフレームワークとして、「人、組織文化、プロセス、技術、知識」の5項組をあげている。彼はナレッジマネジメントを支える五つの主要概念として暗黙知と形式知、コード化戦略と個人化戦略、知識マーケット、実践の場、無形資産を指摘し、ナレッジマネジメントを実践するプロジェクトのタイプ分類を試みている。
3.1.3 情報技術による支援
1980年代のクライアント・サーバシステムの導入、グループウェアの普及、インターネットやイントラネットのインフラとしての導入・普及促進を経て、1990年代になってモバイル端末の普及、データウェアハウスの設立、サプライチェーンマネジメントの登場といった情報技術をナレッジマネジメントに導入し成功した事例の報告が相次いで起こった。情報技術としてはグループウェア技術、データベース技術、マルチメディア技術を中心に各種マイニング技術、情報フィルタリング技術、アウトラインプロセッサ技術が活用されている。すなわちインターネット上に、知識を取り扱うための知的技術が実装され、人間中心のユーザインタフェースを備えた情報システムによるナレッジマネジメントが期待されている。
この動きを受け、新しいナレッジマネジメントソフトの販売、ソリューションサービスやコンサルティングサービスの登場、付随する教育・訓練・調査・出版業界の胎動が起こり、新たにナレッジマネジメント市場が形成されるようになってきた。最新の調査によると、米国では1999年での市場規模予測はほぼ50億ドルと言われている。
情報処理業界と密接に関連するナレッジマネジメントソフトの販売に眼を転じると、いくつかの注目すべきソフトウェア(9) が登壇してきた。データウェアテクノロジィー社のKnowledge
Management Suit 、ロータス社のLotus Notes/Domino R5.0 、マイクロソフト社のMicrosoft Site Server
3.0 が注目されている。国産ソフトとしては、NEC のStarKnowledge 、三谷産業のSELFシステム、NTT データ通信のKnowledge
Serverがある。具体的事例として最も整備されているのは、アーサーアンダーセン社のMicro soft SiteServer 3.0上に構築されたKnowledgeSpaceであろう。
〔関連WWW サイト(9) 〕
|
3.1.4 実践事例報告
日本初めての国立大学院大学の教授になって、8年経った。この間、新設の情報科学センター長を6年勤め、知識科学研究科の創設スタッフに加わり、1999年4月から情報科学研究科教授から知識科学研究科教授に移籍した。国立の研究機関特有のコラボレーションに関する諸問題に直面しながら、民間企業の研究所に18年間いた経験を生かし、それら諸問題の解決に奔走してきた。ここでは、そのなかでナレッジマネジメントおよび情報技術に密接に関連する話題を取り上げたい。
1)JAIST情報環境を利用したサービスシステム
JAISTでは、教職員・院生を含め一人一台のワークステーションあるいはパーソナルコンピュータの情報環境がインフラストラクチャとして提供されている。この情報環境を活かすべく最初はボランティア・グループ中心に各種のサービスシステムが開発されてきた。ホームページの整備、修士論文・博士論文等の公開、広報部門によるJAIST ニュースの発行はいうに及ばず、学生による授業評価システム、セミナー室等の予約システム、就職指導システム等のユニークなサービスシステムが定着している。
2)シャトルバスの開通
金沢と小松の中間という「地の不利」のせいで、JAIST の足回りは非常に悪い。金沢市内からの路線バスは朝夕一便の状態であった。講演者も最初の半年間、車の免許を持っていなかったので、毎夜タクシー帰還の有様であった。そこで当然、教職員・学生から路線バスの整備の大号令が起こるのだが、いつまで経っても埒があかない。山の中の大学院大学で人数が少ないのが災いして、地元の行政機関が運動するも、採算が合わないとバス会社は動かない。事務局の主要メンバもやりたいという意向は持っていることをうすうす確認したが、「前例がない」というお役所主義で躊躇していた。そこで1994年の秋にインフォーマルに何が問題かを私なりに分析したところ、財源の問題と交通事故時の対策の問題が主要な課題と分かった。たまたま当時の研究科長から材料科学研究科の某教授を紹介された。彼の話だと材料科学系では、実験での事故を想定し学生全員、掛け捨て保険に入っていることが分かった。そこで保険屋さんに会った所、「次年度の4月から通学路も保険の対象になる」という吉報を聞いた(このナレッジのもつ重要性に気づいた)。そこで財源は教官の校費負担、関係者全員掛け捨て保険に入るという名案が浮かび、総務部長・会計課長・副学長・学長とミドルアップダウンにキーパーソンを説得した。その後、紆余曲折の説得工作があったが、その詳細は紙数の関係で省略する。現在、本学の本予算の中で地元の鶴木駅とJAIST の間をピストン往復するシャトルバスが、土日も含み無事運行している。すなわち結果的に教官の校費負担は0で運用している。
3)研究費執行管理システムの研究開発と全学利用
1995年9月末の卒業式打ち上げパーティで事務局長、会計課長と雑談していた。このとき「常に予算残の分かる研究費執行管理システムがあるといいね」という話をしていて、研究科長と図書館長も多いに賛同した。1995年10月の教授会で、私が出席していなかったのにも係わらず「情報科学センターに上記システムを作ってもらおう」という決議がなされてしまった。酒の席での発言が自分自身に振りかかってきた。そこで私とセンターの敷田助手は事務局側の全面協力を経て、本学の伝票管理ワークフローの実態を調査した。
企業では当然の如くやっているサポート業務なので、最初は既存のグループウェア、例えばワークフロー管理システムを導入すればいいと気楽に考えていた。ところが極めて恵まれた情報環境と言われる本学でも、それでは実現が困難と判断した。その理由の第一は教職員のそれぞれが自分の好きなメーカのパソコン等を利用しているということであり、大学という組織は極めてヘテロなハード、ソフト混在文化ということを認識させられた。結果的に、全員の使えるツールは電子メール(今ならWWW)のみということが分かった。しかも国立機関特有の会計検査院の会計検査に耐え得るシステムにするために、各種の工夫が必要と分かった。
そこで敷田が同年12月末までに第-1版を試作、2-3 の教官がこれを試行し、デバッグ・改良し、1996年4月より第0版を情報科学研究科全体で運用し、評判が良いので順次、材料科学研究科、知識科学研究科と全学で使用ということになった訳である。このシステムの詳細は文献(10,11)
を参照していただくとして、日本特有の「ハンコ」行政や会計検査に耐え得るような伝票の特注、ドットインパクトプリンターの使用、相見積り書の添付等の工夫を行った。既存のワークフロー管理システムは全ての情報が電子的なビットに変換されてインターネット上を流れているという業務フロー改革を前提に構築されている。我々のシステムは国の制度等により、電子化することの出来ない実世界上の業務フローの存在を認め、これに合わせて実世界指向のワークフロー管理システムを構築(10,11)したことに、その特徴がある。勿論、そのWWW
版も試作(5) した。結果的に、土日や深夜も、出張先や自宅からも出張伝票・注文伝票の依頼ができ、極めて便利な研究費執行管理システムとして定着している。
4)WWW アウェアネスシステム
ネットワーク上の分散環境会議に変えた途端、対面環境の会議では当たり前の各種情報の伝達がアウェア(知覚)されなくなる。電子メール、WWW 、グループウェア、マルチメディアグループウェアのどれを使おうと、所詮、視覚と聴覚のみに訴えることになり、触覚、嗅覚等の情報のアウェアネスも失われてしまう。また視覚情報においても誰が誰をみているか、彼らが今何をしているか、誰の回りに誰がいるかといった各種の情報が欠落してしまう。WWW 上のブラウジング作業において、誰が同じホームページをみているか、そのホームページのどこを見ているか、そしてそれを見て感じたことを赤ペンで表示できるような仕掛けを提供するのが、富士通北陸システムズと我々で共同開発したWeb アウェアネス表示環境WebCoordinate (15)である。このシステムの有効性は遠隔レビュー等で確認(20)され、現在地元の大学での本格運用を目指して、教育システムとしてチューニング中である。
5)WWW探索アウェアネス
WWW上で複数の人間で協力しあってブラウジングしようとしたとする。その際、我々は既存のWWW環境では、複数の人間が探索しているという行動の把握、しかも他者がどの辺りのWWW空間を探索しているかの実態を認識できない。そこで、共同してWWW 空間を探索するのに有用なURL 表示の可視化とそこでの視点のリアルタイム表示を行い、ブラジングを協調して行う行為をWWW 探索アウェアネス(あるいはコラボレーションブラウジング)と呼ぶ。WWW 探索アウェアネス情報を提供するシステムを坂本が試作(21)した結果、他人の存在、動作をある程度予測でき、他ユーザとの円滑なコミュニケーションを促進し、一人では見つけられないホームページを多数見つけ出せることを実証した。ホームページ間の位置関係の空間配置は、リンクのジャングルを探索する際の手掛かり情報を提供する。納豆ビューの探索モードでの改良版とも言える。
6)カンバセーションアウェアネス
インターネット上でテキストベース・コミュニケーションを行う割合は圧倒的に多いが、その際仲間同志のコミュニーケーション過程のリアルタイムでの実態を分析表示する社会性指向ツールはほとんど存在しない。実世界における社会的コミュニケーションと同様な誰が話者で、誰が聴者なのか、誰が誰々に対して発話しているのか、聴者は誰に対して発話を返したか、誰が特定のキーワードに関して特に発話頻度が高いか、あるいは発話したのかといった発話状況をリアルタイムに表示することで、カンバセーションアウェアネスの提供を試みた。これらのメタ情報をリング上の空間配置状況としてリアルタイムに表示するシステムを、伊藤が構築(2) した。その結果、カンバーセーションアウェアネス表示機能のない通常のグループメイルに比べて、メッセージ総数や平均文字数で、それぞれ50%や71%の増加が見られた。また対話関係の成立率の18%の上昇や対話継続回数の46%の増加も見られた。特に、継続的対話関係の支援において、本システムが極めて有効であることが実証された。
3.1.5 日米ナレッジマネジメント格差解消の方策
ナレッジマネジメントに関する調査、我々の組織内でのナレッジマネジメント実践事例を通じて、幾つかの教訓を得た。それらを箇条書きすると、つぎのようになる。
3.1.6 日米の情報技術格差の根源
1980年代の日本企業の奢りを横目に睨みながら、ゴア副大統領の情報通信ハイウェイ計画、クリントン大統領の新千年紀に向けての情報技術フロンティア計画等を通して、米国は1990年代に入って情報技術を駆使したインフラ構築と企業革新を徹底的に成し遂げた。
米国と日本の景気の動向に端的に示されているように、米国は様々の組織のインフラの整備等を通して、インターネットを中心とするグローバリゼーションを成し遂げ、極めて効率的なもうかる組織を世界市場相手に構築した。こうして日米の景気構造は逆転し、日本は産業構造の情報技術遅れの現状に四苦八苦している。
このことはナレッジマネジメント市場においても同様である、ナレッジマネジメントは当初から形式知中心のコード化戦略と呼ばれるものと、暗黙知中心の個人化戦略と呼ばれるものが存在した。欧米は前者に秀でており、日本は後者に秀でていることは歴史の教訓であるが、急激な情報技術化、インターネット化、グローバリゼーション化が欧米に味方したのは、衆目の一致するところであろう。企業のリストラ、ビジネスプロセスリエンジニアリング、M&Aに代表される組織革新を経て、欧米企業は過激なまでに変身した。その結果、組織のフラット化、効率化が起こり、短期での企業利益は向上したが、人の移動が激しくなり、それぞれの組織のコアコンピータンスを担っている知識人が流出した。ここに新たなコーポレイツ・アルツハイマーという知の流出現象が起こった。そこで再び野中の知識創造企業が注目され、野中は「ナレッジマネジメントの父」と称されだしたのである。
一般に日本の情報技術が遅れた理由として、次のような理由が知られている。
参考文献
|
[1]
|
アーサーアンダーセン・ビジネスコンサルティング編:図解ナレッジマネジメント、東洋経済新報社、1999. |
|
[2]
|
伊藤禎宣、國藤 進: カンバセーションアウェアネス支援:カンバセーション状況の視覚化による新たなコミュニケーションツールの提案、人工知能学会第39回人工知能基礎論研究会、東京電機大学、人工知能学会研究会資料SIG-FAI-9903,pp.87-92,1999年11月26日. |
|
[3]
|
加藤直孝、國藤 進: 異なる評価構造を持つ参加者間の合意形成支援法の提案と実装、情報処理学会論文誌、Vol.39, No.10,pp.2927- 2936,1998 年10月. |
|
[4]
|
門脇千恵、爰川知宏、山上俊彦、杉田恵三、國藤 進:情報取得アウェアネスによる組織情報の共有促進、人工知能学会誌、Vol.14,No.1, pp.111-121,1999年1月号. |
|
[5]
|
木村緒理恵、敷田幹文、國藤 進: 実世界ワークフロー管理システムの実現に関する研究、情報処理学会DiCoMo論文集、pp.527-532、1997. |
|
[6]
|
國藤 進: オフィスにおける知的生産性向上のための知識創造方法論と知識創造支援ツール、人工知能学会誌、Vol.14, No.1, pp.50-57, Jan. 1999. |
|
[7]
|
黒瀬邦夫: 富士通のナレッジマネジメント、ダイヤモンド社、1998. |
|
[8]
|
ビル・ゲイツ: 思考スピードの経営、日本経済新聞社、1999. |
|
[9]
|
斎藤主税:ナレッジマネジメントにおける情報技術の動向、北陸先端科学技術大学院大学國藤研究室セミナーレポート、1999年9月13日. |
|
[10]
|
敷田幹文: 研究費執行管理システムの使い方、北陸先端科学技術大学院大学内部資料、1996. |
|
[11]
|
M. Shikida, C. Kadowaki and S. Kunifuji: Towards a Real-world OrientedWorkflow System -Based on Practical Experiments for Three Years-, Proceedings ofKES'99, Adelaide, pp.46-49, 31 August, 1999. |
|
[12]
|
専門図書館、特集: ナレッジ・マネジメント、pp.1-25, No.176, 1999-II. |
|
[13]
|
情報の科学と技術、特集=ナレッジ・マネジメント、pp.429-463, Vol.49,No.9, 1999. |
|
[14]
|
Diamond Harvard Business:「特集」ナレッジ・マネジメント、1999年9月号. |
|
[15]
|
中川健一、國藤 進: アウェアネス支援に基づくリアルタイムなWWW コラボレーション環境の構築、情報処理学会論文誌、Vol.39,No.10, pp.2820-2827, 1998年10月. |
|
[16]
|
野中郁次郎: 知識創造の経営、日本経済新聞社、1990. |
|
[19]
|
野村総合研究所: 経営を可視化するナレッジマネジメント、野村総合研究所広報部、1999. |
|
[20]
|
藤田充典、中川健一、國藤 進: 共有WWW による遠隔レビュー作業の効果に関する考察、情報処理学会主催、DICOMO'99 シンポジウム、pp.501-506, 1999年6月. |
|
[21]
|
坂本竜基、國藤 進: コラボレーションブラウジング:WWW アウェアネスを利用した新しいブラウジング方式の提案、人工知能学会第10回"AIシンポジウム'99"、早稲田大学国際会議場、人工知能学会資料SIG-J-9901,pp.97-102,1999 年12月18日. |
本稿では、音声認識の現状を概観し、今後の展開の方向と可能性について検討する。
3.2.1 音声認識技術の現状
3.2.1.1 現状の位置付け
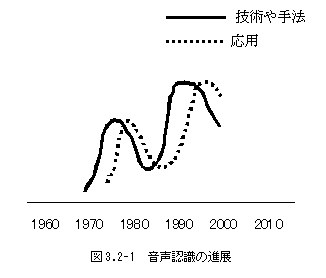
図3.2-1は、近年の音声認識の手法および応用の進展を、概念的・主観的に表したものである。基本的な技術や手法に関しては、1970年代に、DP(動的計画法)などを中心に、ひとつの山を形成し、1990年前後に、HMM(隠れマルコフモデル)を中心として、次の山を形成した。応用に関しては、技術・手法の確立からしばらくして、ピークを迎えると考えられるが、それ以外にも、計算機の処理性能(記憶容量や処理速度)の進歩による影響が大きい。特に最近の音声認識製品の一般への普及は、パーソナルコンピュータの高性能化を抜きには語れない。しかし現在は、そのような応用が一段落しつつある時期と見ることができ、今後の新たな方向性を探る段階にあると言えよう。
3.2.1.2 確立されている手法
次に、現在確立されている音声認識手法の概要を述べる。現在主流となっている統計的音声認識の枠組みは、以下のように定式化される。
![]()
このとき、 P(x|w)を音響モデルに、P(w)を言語モデル対応させることにより、認識スコアは、「音響モデルの尤度 + 言語モデルの尤度」で表されることになる。通常、音響モデルには、音素を単位とするHMMを単語辞書に基づいて連結したものが用いられる。言語モデルは、範囲の限定された小さいタスクでは、構文的文法やネットワーク文法などが用いられるが、ディクテーションなどの大語彙タスクでは、そのような文法を記述することが事実上不可能であるため、連鎖統計モデルが用いられる。連鎖統計モデルは、n-gram とも呼ばれ、n個の単語の並びが出現する確率を統計的に求めたものである。
3.2.1.3 現在の手法の問題点
今後の展開の方向性を探るための材料として、このような統計的枠組みの問題点を検討してみる。
統計的手法のベースとなるモデルは、マルコフモデルにしても連鎖モデルにしても、シンプルなものである。しかし、枠組みはシンプルではあるが、パラメータを増やすことにより、モデルの精度を容易に向上させることができる。例えば、マルコフモデルの状態数や出力分布の混合数を増やしたり、前後の音素を考慮して音素モデルの種類を増やす、また、連鎖モデルの連鎖数を増やすなどにより、モデルの精度が上がる。ただし、パラメータが多くなると、それに応じて、学習用のサンプルが大量に必要になる。このような枠組みは、近年のように計算機の処理能力が飛躍的に伸びる状況では、たいへん都合がよい。すなわち、演算速度が上がれば、それに応じてモデルのパラメータを増やすことができ、記憶装置の容量が増えれば、学習用サンプルを増やすことができる。
しかし、このような性質は、利点であると同時に限界でもある。上記のようなサイクルを繰り返していっても、認識対象と似たものが、学習用サンプルに含まれていなければ、認識率は改善されない。例えば、想定外の声質や想定外のノイズ環境があれば、それを学習用サンプルとして取り込んで、また学習することになるが、その後もまたミスマッチが生じる可能性が解消されることはない。
このような循環的な構造から脱却する枠組みを見出すことが、今後のブレークスルーとなると考えられる。
3.2.2 音声認識の今後の方向
音声認識の研究および応用の今後の方向について、現在の認識方式を用いる場合と、新たな認識方式を開発する場合に分けて検討する。
3.2.2.1 既存の認識方法の応用
現在の音声認識の性能は、ノイズの少ないはっきりした発声で、内容が言語モデルにある程度適合していれば、大語彙のディクテーションでも90%以上の認識率が得られまでになっている。人間には遥かに及ばないが、この程度の性能に限っても、応用できる範囲はかなり広いと考えられる。しかし、パソコン用のディクテーションソフトが広く普及し1 、 試用程度に使われる機会は増えたと見られるが、継続的に実務に使われている例は多いとは言えない。その原因を検討し、現在の認識方式の延長で、応用を広げる可能性を探る。
1 IBMのViaVoiceの1999年の売上げは、国内で100万本を超えたと発表されている。
3.2.2.1.1 ユーザーインターフェースの改良
現在の認識エンジンをそのまま用いるとした場合に、第一に改良の余地があるのは、ユーザーインターフェースであろう。その際に、GUIにおけるアイコンやメニューの選択の代替として設計するか、新たなインターフェースの枠組みを生み出すかが問われる。
また、音声認識対応アプリケーションの開発を容易にするために、APIの設計や標準化が重要になる。APIとしては、Microsoft がSAPI(Speech
API)を提案している。
ハードウェアに目を向けると、入出力用デバイスとして、現在は、安定した認識性能を得られやすいことから、ヘッドセット(マイク付きヘッドホン)が用いられることが多いが、ユーザーにとっては、装置を身につけずに済めばそのほうが気軽である。そのために、マイクロホンアレーを用いて、特定の方向に指向性を集中し、複数話者の分離やS
/ Nを向上させるための研究が続けられている。逆に、目標物の無いところに向かって話すより、電話器のような対象がある方が話しやすい、ということもあるかもしれない。オフィス等では、話し声が漏れないような、防音機構付きのデバイスがあれば有用であろう。このように、心理および機能の両面からの研究開発が必要である。
音声認識が受け入れられにくい理由のひとつとして、使用している状況が自然でない、という点が挙げられる。機械やマイクに向かって話す、という状況は、本人にとっても周囲の人々にとっても違和感が残る。これを解消するためには、人間に話している状況に、できる限り近づけることが望ましい。すなわち、話す対象を、マイクではなく、顔を持った人形のようなものや、画面中のCGによる仮想的な人物とすることが考えられる。また、相手が適切な反応を返すことも重要である。たとえば、ディクテーションソフトでも、ユーザーが一方的に文章を話すという状況は、人間相手とすれば、かなり不自然な状況なので、相槌や合いの手などの反応があると、自然さが改善される可能性がある。また、そのような対話が、ユーザーにとって楽しいものとなるように、シナリオとしての構成力が問われる。
機械からの反応は、音声だけでなく、画像やその他さまざまなデバイスを利用して、マルチモーダルな統合的設計を行うことが望ましい。逆方向も同様で、音声認識だけでなく、視線や表情やジェスチャーの認識など、他の技術との融合が重要であることは言うまでもない。
3.2.2.1.2 認識性能のチューニング
現在の音声認識手法の延長であっても、認識性能の改善の余地は多く残されており、研究が続けられている。
処理の高速化や装置の小型化は、ハードウェアの進歩に負うところが大きいが、プログラムの効率化も重要である。例えば、携帯電話に組込む認識プログラムは、ワークステーション上のものとは異なる規準で、プログラムを設計する必要がある。街頭や車内など多様な環境で利用できるようにするためには、ノイズ対策は重要である。その手法としては、スペクトル・サブトラクションやHMM分解・合成などがあり、改良のための研究が進められている。話者の違いや、発話のゆらぎに対応するために、話者適応化の手法も、各種提案され、不特定話者認識システムの限界を補っている。
このような、チューニングを効率良く行うためには、研究開発用ツールの充実が重要である。例えば、無料で配布されているものとして、OGI(Oregon Graduate
Institute)のものやエジンバラ大のもの、言語モデル用として、CMU・ケンブリッジ大のものなどがある。また、日本でもIPAのプロジェクトで、日本語ディクテーション基本ソフトウェアとして配布している。HMMのプログラム群としては、HTKが広く使われている
2。また、IBMやマイクロソフトが、それぞれSDKとして各種ツールを配布している。
認識精度を向上させるためには、学習用の音声・言語データベース(コーパス)を、できる限り大量かつ多様に収集する必要がある。従来から、それぞれの研究組織で独自に収集が進められていたが、それらをとりまとめ、効率的に収集および配布できるようにするための組織が設立されている。このような組織として、米国でLDC(Linguistic
Data Consortium)が、欧州でELRA(European Language Resources Association)が活動しており、最近日本でも、GSK(言語資源共有機構)が設立された。
2 HTKはケンブリッジ大で開発され、その後商用ソフトとして売られていたが、最近マイクロソフトが買い取り、研究用には無償で配布する方針をアナウンスしている。
3.2.2.1.3 認識対象の拡大
従来の認識システムは、特定の1種類の言語の話者を対象としたものがほとんどであったが、実際の利用者の多様性を考えると、多言語を同時に認識できるようなシステムが望ましい。統計的手法の枠組み自体は、言語に依存しない普遍的なものなので、各言語用の音声サンプルを用意し、その音韻体系がわかれば、同様の手法で各言語用システムを構築できる。それらをひとつの認識システムとするための手法としては、これまでにも、音素モデルの集合を統合するものや、各言語用のシステムの出力結果を尤度に応じて選択するものなどが提案されている。また、OGIでは多言語用に特化した音声データベースを収集・整備している。さらに、話者の多様化・流動化は、単一言語内における多言語化を増大させていくと考えられる。このため、多言語をひとつのシステムで選択的に認識するだけでなく、今後は、多言語が混合した音声を認識できるような技術も必要になる。そのために、音声学におけるIPA(国際音声アルファベット)に相当するような、万国共通の音声認識用単位系の構築を目指す研究も行われている[1]。
他にも、これまでほとんど扱われてこなかった認識対象として、方言、老人、子供、発声器官に障害のある話者などがあり、研究の展開が期待される。
3.2.2.1.4 自然言語処理技術の改良
音声の処理に直接関連する部分(音響モデル)の性能だけでなく、言語モデルを含めた自然言語処理技術の向上が、総合的な認識性能に重要な影響を与えることは明らかである。特に、真の意味での自然な対話を実現するためには、機械による正確な意味理解が理想である。しかし、現在実現可能な技術としての連鎖統計モデルから、次の段階に踏み出すことは容易ではない。現在試みられている次の展開としては、統計モデルと文法的モデルとを統合する研究などがある。また、現在の手法に基づく場合、言語モデルの改良による効果よりも、音響モデルの改良による効果の方が遥かに大きい、との報告[2]もある。
3.2.2.1.5 新規アプリケーションの開拓
新たなアプリケーションの開拓も精力的に進められているが、かつて誰も想像しなかったような新奇なものは、そうあるものではない。しかし、これまで技術的に困難だったものが、可能になっていくことは多い。
処理装置の小型化技術が進むことにより、携帯電話やPDAに組み込み可能になり、ウェアラブルパソコンが現実味を帯びてきた。Ubiquitous Computing
を実現する上でも、重要な要素となるだろう。また、大語彙認識性能の向上により、音声翻訳(自動通訳)装置も、次第に実用に近づきつつある。しかし、SFにあるように、ロボットと自然に対話できるようになるには、やはり、意味理解がボトルネックになり、実現はかなり先になると思われる。
現在、音声認識が一般ユーザーに最も受け入れられているのは、ゲームソフトや玩具の分野であろう。多少の誤認識や意味処理の曖昧さがあっても、影響が少ないという点で、現在の技術水準にマッチしたと言える。しかし、使い勝手さえ良ければ、音声認識は使って楽しいものであるということが実証されたという意味は大きい。それに対して、ディクテーションソフトでは、90%を超える認識率であれば、はじめは驚くほど高い認識精度と感じるが、いざ実用的に使おうとすると不満が出るのかもしれない。
産業的な意味で最も影響が大きいのは、各種の家電に標準的に組み込まれるようになる事であろう。そのためには、認識精度やユーザーインターフェースの改良の他にも、小型化や標準化など多くの課題が残されている。
3.2.2.2 新たな認識・学習手法の開発
ここでは、新たな認識手法を開発する方向での展開を探る。
3.2.2.2.1 新たな音響モデル
音響モデルとして、HMMを超えるような枠組みを生み出すことが、次の大きな進歩にとって最も重要な課題である。別のモデルとしては、従来からニューラルネットの研究があり、HMMと組み合わせたハイブリッド型なども試みられてきたが、通常のHMMを大きく超えるような成果は得られていない。HMMの状態内の表現能力を上げたり、限られた学習用サンプルから妥当な最適化が行われるようにするためのHMMの改良は、数多く提案されているが、いずれもブレークスルーにつながるまでには至っていない。
3.2.2.2.2 新たな学習アルゴリズム
前章で指摘したHMMの問題点も含めて、現在の用いられている統計的手法の持つ本質的な問題のひとつは、入力音声の尤度を全体的に均一に最適化する点にあると考えられる。すなわち、音声が存在する部分も無音部分も、言語的に重要な部分も重要でない部分も、均等に扱われる。重要な部分を集中的に識別するような枠組みができれば、ブレークスルーになる可能性がある。すでに提案されている識別誤り最小化学習や相互情報量最大化学習なども、このような方向性の例と言える。
また、機械学習や知識獲得などのAI的手法や Genetic Algorithmを採り入れる方向も重要になる可能性がある。特に、計算機の容量の増大により、大量のサンプルをそのまま保持して照合するような、事例ベース的な手法が、今後有望になるかもしれない。時系列音声データの中から、言語情報を抽出するという意味では、データマイニング的な視点で見ることもできよう。また、音声認識を複雑系としてとらえ、綿密な処理ができれば、現在の統計的手法のような、単純なモデルを大量のデータで学習させるような枠組みに対するアンチテーゼとなり得るかもしれない。
3.2.2.2.3 様々な環境への対応
ノイズ対策や、複数話者・移動話者への対応のための新たな手法としては、マイクロホンアレーを用いたものの他にも、独立成分分析(ICA)に基づく音源分離手法などが注目されている。
また、音声だけでなく、音の環境を全体として認識・理解しようとする Auditory Scene Analysis の研究も新たな流れとなっており、音声認識にも有益な影響を与えると思われる。
3.2.2.2.4 非音韻的情報の利用
イントネーション、テンポ、リズムなどの非言語的情報やアクセント情報などを利用して、音声認識の精度を補強しようとする試みは、従来から行われてきたが、大きな精度向上には至っていない。また、このような情報から、話者の感情や意図などを抽出して、対話システムなどに利用しようとする研究も行われてきた。しかし、十分な認識精度が得られないことや、正解の判定などの性能評価が難しいことなどから、困難な課題であると言える。
3.2.3 音声技術の方向性
最後に、音声技術の大局的な方向性を探るために、実現可能性は横に置き、理想論を展開してみたい。
3.2.3.1 音声の利便性の本質
ここでは、「音声を使うことの利便性の本質は何か?」ということを理想論として問い直してみる。それをあえて一言でまとめるなら、「気軽な対話による意思の疎通」にあると考える。これは、次のような2つの要素を含んでいる。
1)制約が少ないこと。
2)人間を相手にしているかのように使えること。
1)は、文法的制約、身体的制約、場所的制約などを含む。文法的制約が少ないためには、例えば曖昧な会話文を許容する必要がある。身体的制約が少ないためには、例えば手ぶらで使える必要がある。場所的制約が少ないためには、Mobile
Computing、Ubiquitous Computingといった技術が進展する必要がある。
2)は、ユーザーインターフェースとしての操作対象を、人間のアナロジーで捉えられることを意味する。人間相手のような気楽なインタラクションの過程の中で、目的が達成され、情報が交換され、さらには、楽しさや安らぎが得られる、というのが理想的である。
3.2.3.2 本質的な課題
これらを実現するためには、多くの困難な本質的課題がある。
まず、人間並みの音声認識性能や環境に対する頑健性を実現すること、そして、それも含めて、人間並みの知的能力が実現されなければならない。それには、人間並みの知能や常識を持ち、真の意味理解が可能になることが必要であり、そのためには、人間並みの学習能力および適応能力が必要になる。
そのための方向性は、人間のシミュレーションに向かうと思われる。そのひとつは、従来から続けられている認知科学的アプローチであり、もうひとつは、近年の医療計測技術の進歩により、研究が盛んになってきている生理学的アプローチである。後者は、音声では、発声機構や聴覚機構のシミュレーションにあたる。米国における
Visible Human Project も、これに関連した流れと言える。いずれのアプローチも、現在の時点では、実現は非常に困難であるが、いずれブレークスルーが見出されることを期待したい。
参考文献