(天野英晴委員)
ペタフロップスマシンが1015FLOPSのピーク性能を実現する計算機のことで、しかも5〜7年後程度を目処に実現を狙っているとすれば、大規模並列計算機のプロセッサ数を増やす方向以外に手はない。これは、いかに高性能マルチプロセッサの性能が上がり続けているとはいえ、5〜7年間程度では、10倍を越える性能向上を見込むことができないからである。現在、高性能な浮動小数点演算機能付きマイクロプロセッサの性能は、1GFLOPSつまり109に達していない。したがって、ペタフロップス機を実現するためには、将来、性能が向上することにより数GFLOPSとなった高性能マイクロプロセッサを、10万から100万台接続する必要がある。これは、今まで超並列計算機として考えられてきた1000-10000プロセッサから成る規模をさらに越えている。つまり、簡単に言うと、近未来にペタフロップスマシンの実現を目指すならば、問題は単純にプロセッサ数の増加ということになる。
さて、ペタフロップスマシンがGFLOPSプロセッサを10万から100万集めた超々並列計算機であるとすれば、その鍵を握るのはプロセッサ間を接続する結合網であろう。ところがこの規模のマシンに関して結合網の技術から考えると、決して面白くない結論が速やかに導かれる。結論のみを書くとあまりにも簡単すぎるし、規定原稿枚数に達しないと困るため、まず、現在の大規模並列計算機用の結合網の現状を簡単にまとめ、それからペタフロップスマシンについて論ずる。
結合網で問題になるのは、トポロジすなわちつなぎ方、パケット転送技術および実装技術である。
トポロジ 従来、結合網の研究ではトポロジが重視されてきた。1980年代に流行したハイパーキューブ結合は、その配線量の多さから、高性能のマイクロプロセッサによる大規模並列システムに適合することができず、80年代後半から、実マシンには単純な2次元/3次元メッシュ(トーラス)またはクロスバの組み合わせから成るFat Tree等の間接網が用いられる一方、研究レベルではさまざまな超並列向きの結合網が提案された。しかし、これらの超並列向きの結合網が実際に利用された例はほとんどなく、90年代に入ってからトポロジの研究は下火になり、現在でもその傾向は続いている。この、最も大きな原因は、高性能のマイクロプロセッサに見合うだけの高速なリンクを長く伸ばすことが技術的に難しくなったためである。複雑なトポロジにより、プロセッサ間の距離を短くすることによるメリットよりも、リンクを伸ばしたことによる転送性能の悪化とコストの増加のデメリットが上回ったといってよい。例外は、日本の超並列計算機プロジェクトで、CP-PACSのハイパークロスバ、RWC-1のhMDCE、JUMP-1のRDTなど新しい結合網を積極的に用いており、一つの特徴といってよい。
パケット転送技術 トポロジに代わって80年代後半から技術革新が起きたのはパケット転送技術である。初期の大規模並列計算機はパケットの転送をソフトウエアで行ったため、パケットの転送はハンドシェークを伴う単純なStore-and-Forwardであり、他に手の打ちようがなかった。ところがLSI技術の進展により、プロセッサと独立したルータというハードウエアが作られるようになってから、ルータのハードウエアが用いるさまざまなパケット転送技術が発達した。
DallyらによるWormholeルーティングと仮想チャネルの技術の確立により、デッドロックの心配をすることなく結合網の性能を最大限利用可能になった。90年代に入ってパケットの転送技術の最後のテーマは、適応型ルーティングの技術の確立であった。適応型ルーティングとは、パケットの転送経路を固定せず、結合網の混雑を判断して迂回する技術である。90年代の前半、さまざまな方法が提案された末、最適経路に関してはDuatoの方法、迂回を許す場合はTurnモデルなど実装可能な方法が登場した。現在、パケット転送技術の研究は一息ついて、今まで提案された方法の中で実際的なものに関して、実際のルータチップを作って実マシン上でテストする段階に入ったと言っていいようだ。
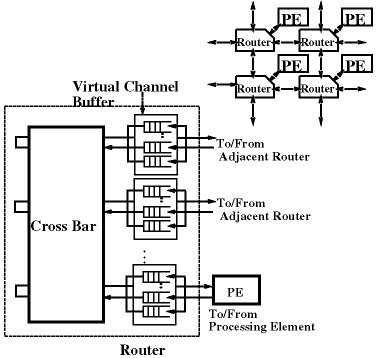
実装技術 トポロジの研究、パケット転送技術の研究が共に一息ついた現在、それらをいかに生かしてルータチップ上に実装するかが重要になってきている。そこで、ここでは多少詳しく最近のルータチップに関して紹介する。はじめにルータの機能と構造について説明する。典型的なルータは、図1に示すように、パケットを格納するバッファと交換するスイッチ、転送と交換を制御するコントローラから成る。
最近のルータは、パケットを効率良く転送するためWormholeルーティングまたはVirtual Cut throughと呼ばれる方法をとっている。また、リンクの利用効率を上げデッドロックを防ぐため、仮想チャネル(Virtual Channel:VC)を複数装備している。最近のルータのいくつかについて特徴をまとめて表1に示す。
| ルータ | T3E | Cavallino | RWC-1 | JUMP-1 |
| 開発 | Cray | Intel | RWCP | 慶應大 |
| トポロジ | 3D Torus | 2D Torus | hMDCE | RDT |
| ダイサイズ(mm) | 16.7 | 13.5 | 13.6 | |
| 動作周波数(MHz) | 75 | 200 | 50 | 60 |
| 転送レート(MHz) | 375 | 200 | 100 | 60 |
| リンクバンド幅(MB/s) | 600 | 800 | 300 | 38 |
| チャネル幅(bits) | 14 | 16 | 24 | 18 |
| 使用ゲート数 | 81917 | 50000 | 90522 | |
| 使用ピン数 | 350 | 409 | 299 | |
| テクノロジ(μm) | 0.35 CMOS | 0.35 CMOS | 0.7 CMOS | 0.8 BiCMOS |
T3E[1]はCray/SGIがT3Dに続いて開発した大規模並列型スーパコンピュータ用ルータである。このルータの特徴は、簡単な故障迂回機構を内蔵していること、Duatoの方法を利用した最短経路上での適応型ルーティングを装備していることで、90年代のパケット転送技術研究の成果を積極的に利用している。一方で、0.35μm CMOS低電圧テクノロジの利用により375MHzの転送周波数を実現しており、リンクの駆動も直接可能である。
Cavallinoルータ[2]は、T3Eのように凝った転送機能を持たない単純な構造を持つルータで、2次元メッシュの接続用の4本の物理リンクとプロセッサと接続するための2本のリンクを持っている。ルーティングアルゴリズムも単純なdimension-order routingである。
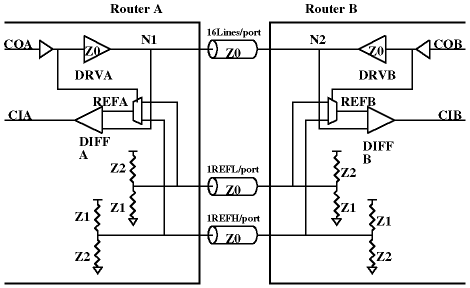
このルータの凄い所は、リンク間およびリンク、制御信号は、Bidirectional Signaling法[3]により1本の線で全二重通信を実現している点である。図2のDRVA,DRVBより送り出された信号は3レベルの電圧にエンコードされリンク上を伝わる。このリンク上の信号と自分が送り出した信号を用いてデコードすることにより相手が送り出した信号を取り出すことができる。両側から送られた信号は途中でぶつかるのだが、自分の出した信号は反転信号によりキャンセルされるので、相手が送った波形のみ取り出すことができる。
RWC-1[4]のネットワークは、hMDCEと呼ばれる階層3次元直接網である。これは、x-y平面をc-Banyan(circular Banyan)、x-z平面をCCC(Cube-Connected Cycles)で結合したものである。hMDCEの各ノード部分はsub-networkノードと呼ばれ、4PEから構成されている。このルータは、RWC-1のアーキテクチャを反映した特殊な機能を持つ。まず、リアルタイム処理のマルチユーザ環境を実現するために、パーティション間で通信干渉の無い閉パーティションを構成する事ができる。ルータは、パーティション制御のためのレジスタを持ち、パーティション外に出ようとするユーザパケットをエラー処理する(空間分割支援)。また、プロセス切り替えの際アプリケーションやOSの要請により、ルータ上に残っている未配送パケットをローカルメモリ内に保存、復活する機能も持つ(時間分割支援)。
JUMP-1[5]ルータは、分散共有メモリ管理用にマルチキャスト機能と応答パケット収集機能を持つ点が特徴である。マルチキャストは、結合網RDT(Recursive
Diagonal Torus)の階層構造を利用し、パケットヘッダ内のビットマップに応じて行われる。他のルータとの違いはBiCMOSテクノロジを利用していることで、2m近いケーブルをECLレベルで直接駆動することができる。RDTはリンク数が多いことと、テクノロジがやや古いため、転送性能は他のルータに比べて低い。
以上をまとめると、最近のルータは、
ということがわかる。
(1)ペタフロップスマシンはどんな構成になるか?
さて、結合網の点から現在の大規模並列計算機と、5−7年後の完成を目指したペタフロップスマシンを比較すると表2のようになる。
| 現在のマシン | ペタフロップスマシン | |
| プロセッサ性能(GFLOPS) | 0.1 -1.0 | 1.0 - 10.0 |
| プロセッサ数 | 100 - 1000 | 100000 - 1000000 |
| リンク転送容量(MB/sec) | 100 - 500 | 1000 - 5000 |
ここで、単体プロセッサ性能の性能向上に見あっただけのリンク転送容量は、おそらく先に示した現在の最新鋭のルータ技術、すなわち低電源CMOSの延長線上で実現可能であろう。とはいえ転送クロック周波数は500MHzを越えることは実装が困難であるので、それから先はバンド幅、すなわち線の数を増やすことになる。Cavallinoルータが用いた双方向転送の技術はこのような状況では大変有効である。この周波数で転送を行うためには、一つの線上に連続していくつもパルスを送るWave Pipeliningの技術の利用が不可欠となる。
一方、100万プロセッサを実装する場合のスペースの問題はどうであろうか?1メートル四方の基板に100プロセッサを実装することは、MCM(Multi Chip Module)や1チップ上に複数のプロセッサを搭載する技術により可能になると思われる。その場合、この基板を10×10×100の直方体状に配置すると、一辺が約10mとなり、高さは数m程度になる。この大きさは実現可能でないとはいえない。
ところが、この大きさになると、いかにWave Pipeliningを効果的に用いたとしても、500 MHzでパケットが通るリンク(しかも1つのリンクの同軸ケーブル数は増やさなければならない)を、遠隔プロセッサに対して配線することはほとんど不可能といってよい。したがって、この規模になれば3次元Mesh/Torus以外、結合方式は考えられない。Torusのフィードバックループを心配する向きもあるが、これについては実装上の工夫[6]や、マッピングの工夫[7]で解決可能であるのでさほど心配は要らない。もちろん、効率良く動作するアプリケーションも隣接プロセッサ間でのみデータを交換する単純な陽解法的な数値計算に限定される。これは、PACSプロジェクトを指導した筑波大学の星野力教授、慶應大学の川合敏雄教授がかつて予想した世界である[8][9]。すなわちペタフロップスマシンはスーパーPACSにならざるを得ない。
(2)ペタフロップスマシンは存在価値があるか?
ところで、このような巨大なマシンが一つのシステムとして実装されている意味はあるのだろうか?例えば、ペタフロップスマシン1台よりも、10TFLOPSマシン100台を巨大なバンド幅を持つ情報スーパーハイウェイで接続した方がいいのではないか?
10TFLOPSマシンを例えば10×10×100の3次元Torusで実現した場合、境界プロセッサ数は、100×4+1000×2=2400となる。ペタフロップスマシンの一つのリンクは1000MB/secの転送容量を持っているので、これと同じプロセッサ間転送バンド幅を実現するためには、10TFLOPSマシン間を接続するスーパーハイウェイは、 2400 GByte/secの転送容量を必要とすることになる。これは、いかに光転送技術と大容量の交換技術が発達しても実現は容易ではなく、まして既存のネットワークを利用するということは現実的ではない。このように、ペタフロップスマシンは、技術的には一つのシステムとしてまとまっている価値が十分存在するのである。
(1)次に何を調査すべきか?
今まで検討したシナリオに基づけば、ペタフロップスマシンはできる限りシンプルな構造が良い。したがって、計算機アーキテクチャ屋のやるべきことは、耐故障性の検討以外全くないといってよい。ちなみに、OS屋のやるべきこともほとんどない。2次元/3次元Torusの耐故障性に関する検討は、すでに多くの研究が行われており、この中から現実的な方法を見つければよい。したがって、以降、この委員会の調査活動は、アプリケーション、記述法、実装技術、耐故障性の検討に専念し、とりあえず計算機アーキテクトには全員お引き取りを願うのがよい。筆者も含め計算機アーキテクトは、その研究が飯の種であるため、マシンを複雑にする傾向にあり、ペタフロップスマシンの研究開発には害の方が大きい。PACSやGRAPEの開発が計算機の専門家によらなかった点を考慮すべきである。
(2)わが国として取り組むべき課題
上記の議論から、結論として、わが国としては軍事予算を大幅に削って、ペタフロップスマシン=スーパーPACSの開発を迷うことなく即座に開始すべきである。軍事予算で開発するのは、核兵器の実験が禁止される以上、実験に代わり得る計算を行うことのできるペタフロップスマシンこそが最大の軍事的抑止力になるという考え方に基づいている。(この考えを筆者自身は信じていない。実験せずに計算だけで創り出せるものなどあるわけがない。しかしもはや現在の日本には他に資金のあてはないし、ペタフロップスマシン=軍事抑止力という考え方は案外真面目に信じられているようなので利用しない手はない)。PACS型の計算機は日本独自の考え方に基づいており、Originarityという点で他国からクレームが出る心配は全くない。将来にわたっても商売にならないから、貿易摩擦も心配ない。これを日本が始めれば、米国をはじめとして各国も競って軍事費を削って(他国だってお金はないので)ペタフロップスマシンの開発を始めざるを得ないであろう。このことにより、破壊と殺人以外使い道のない兵器を開発するお金を使って、地球の温暖化対策をはじめとして、我々がこれから地球上に生き残っていくために必要な研究に使う道具を得ることができるのである。
<参考文献>
(稲上泰弘委員)
1980年代にベクトルプロセッサ型スーパーコンピュータが普及し、超高性能計算需要を喚起し加速させた。日本のスーパーコンピュータメーカは、汎用計算機で培った超高速バイポーラLSI技術を活用し、世界最高性能のシステムを市場投入し続け、ギガフロップスマシンを実現した。ハードウエア技術、アーキテクチャ技術、ソフトウエア技術の全般にわたり世界をリードしてきた。
1990年代に入り並列プロセッサへの期待が高まり、1990年代半ばを過ぎた現在、性能が1〜2GFLOPSのベクトルプロセッサを数百台規模で結合した並列ベクトルプロセッサや、300〜500MFLOPSのスーパスカラプロセッサを1000台規模で結合した超並列プロセッサが実用化され、テラフロップスマシンの時代に突入した。使用されるハードウエア技術はCMOSテクノロジが主流となり、ここにおいても世界をリードするポジションにある。[1]
超高速計算が必要な最先端の計算科学分野ではさらに高速なスーパーコンピュータが必要とされ、2000年代にはペタフロップスマシンに向けた新たな技術開発が望まれている。一方、スーパーコンピュータ市場は頭打ち(横ばい)との予測が一般的で、これまで性能最優先で進められてきた技術開発のあり方に疑問を投げかける議論も出ている。ペタフロップスマシンの実現に必要な技術が、最先端の計算科学研究者にとどまらず、広い範囲の研究者・技術者にとって役に立つ計算機に広く応用されることが必要なことを示唆している。
本節では、ペタフロップスマシンを実現するための重要課題について考察する。
ペタフロップスマシンの実現に並列プロセッサ技術は不可欠であるが、一つの問題を並列処理した場合の処理時間の内訳は次のようになる。
| 逐次処理 | データ転送(並列処理可能) | 計算処理(並列処理可能) |
すなわち、並列処理ができない逐次処理部分の実行時間、多くの場合並列処理が可能なプロセッサ間データ転送時間およびプロセッサでの計算処理時間である。高い並列処理性能を実現するには、アルゴリズム/プログラミング手法の工夫、アーキテクチャ/論理方式の工夫などハード、ソフト両面の高い技術が必要である。アルゴリズム/プログラミング手法の工夫としては、逐次処理時間をほとんどゼロにすること、計算処理とデータ転送処理をできるだけオーバラップさせ実効的なデータ転送時間を少なくすること、計算処理の並列度を高めることがある。アーキテクチャ/論理方式面では、単体プロセッサ性能の向上、低レーテンシ・高スループットのプロセッサ間データ転送機構の実現が鍵となる。ここでは、アーキテクチャ/論理方式に関連する課題について考察する。
1ペタフロップスマシンの実現を考える場合、どの位の性能を持つプロセッサを何台程度結合するかが第一の課題となり、実現可能かつ広い応用で実用可能な範囲で決定する必要がある。表1に、1ペタフロップスマシンの実現を考えた場合の、プロセッサ台数とプロセッサ単体性能との組み合わせ例を示す。以下、表に示した3組のアプローチの実現性について考える。
| 項番 | プロセッサ台数 | プロセッサの 単体演算性能 |
プロセッサ性能実現のために 必要な動作周波数、 命令/演算実行並列度 | |
| 1 | 1,000 | 1TFLOPS | 2GHz | 500 |
| 2 | 10,000 | 100 GFLOPS | 2GHz | 50 |
| 3 | 100,000 | 10 GFLOPS | 2GHz | 5 |
(1)プロセッサ台数
現在実運用されている最も性能の高いシステムの並列度は1000台規模である。1000台規模のシステムを高い稼働率で使うことは決して簡単なことではなく、かなりの工夫が必要とされている。今後、並列アルゴリズム、並列プログラミング技術の発展を期待するとしても、実用レベルで使用できる並列度は現状の一桁程度上が限界と考えるのが妥当である。したがって、実用的なペタフロップスマシンのプロセッサ並列度は高々10,000台規模である。表1に示した3つの組み合わせの中で、項番3は特定の応用を除けば採用できない方式と考えざるを得ない。
(2)プロセッサ単体演算性能
プロセッサ単体の演算性能は、プロセッサの動作周波数および命令/演算の実行並列度で決まる。最近の高速プロセッサの動作周波数は500MHz前後まで向上し、今後も高速化が図られると予想される。今後10年の間に現状の4倍の2GHz程度は実現されると期待したい。命令/演算の実行方式はスーパスカラが主流であり現在2ないし4の並列度が一般的である。VLIWなどの新しいアーキテクチャの導入により、今後10年の間に少なくとも16ないし32の命令/演算の並列実行方式が実用化されると考えられる。しかしながら、1プロセッサにおける数百レベルの命令/演算の並列実行は、プロセッサチップ構成方式、コンパイラ方式いずれの観点からも実用性が低いと言わざるをえない。したがって、表1・項番1に示したプロセッサ単体性能1TFLOPSの実現は、用途を限定しない限り実現性は低いといえる。
(3)ペタフロップスマシン構成のガイドライン
以上のことより、今後10年以内にペタフロップス級のマシンを実現する場合、プロセッサ並列度は数千から1万台規模、プロセッサ単体の性能は高々100GFLOPS程度とする構成方式が妥当である。
(4)メモリ構成方式
プロセッサ単体の性能は、命令/演算の並列実行機構だけでなく、メモリとレジスタ/命令実行機構との間のデータ供給能力(レーテンシ、スループット)にも影響される。レーテンシはキャッシュ機構を導入することにより解決してきており、今後も技術開発が進められる。スループットについては、キャッシュをプロセッサチップに外付けする場合はLSIピン数の制約を受けるが、今後はLSIの高集積化に支えられたロジック・メモリ混載LSI技術の進展により、チップ内で高スループットのキャッシュの実現が可能と考えられる。
超高性能計算機を必要とする応用の中には、プログラムのワーキングセットが大きく、キャッシュが有効に働かないものがある。ベクトルプロセッサなどでは、キャッシュ機構を使わず、レジスタと主記憶との間で直接データのやり取りを行い、かつアクセスリクエストの先行制御、データ転送のパイプライン処理により性能を高めている。ベクトルプロセッサの場合、1FLOPS当たり4〜16B/sのスループットを実現して高い実効性能を維持してきているが、ペタフロップスマシンのようにプロセッサ単体性能が100GFLOPSオーダになると、数百GB/s〜TB/sのスループットをプロセッサチップとメモリチップ間で実現する必要があり、実現性・コスト面で無理が生じる。ここにおいてもロジック・メモリ混載LSIの活用によるチップ内高スループット主記憶を基本とする必要があるが、容量面で制約が生じ、プロセッサ性能、メモリ性能、メモリ容量のバランスを考慮した並列アーキテクチャの追求が重要となる。しかしながら、このような方式を広い範囲の応用に適用することは難しいと考えられ、基本的には、ロジック・メモリ混載LSI技術を念頭においたキャッシュ方式、階層記憶方式を追求する必要がある。
(5)プロセッサ間結合方式
並列プロセッサの稼働率を高めるには、全実行時間に占めるプロセッサ間データ転送時間の割合を少なくする必要があり、アーキテクチャ/論理方式面では、低レーテンシ・高スループットのプロセッサ間結合方式の実現が重要である。
現状システムのプロセッサ間データ転送レーテンシは、通信ライブラリMPIのレベルで考えると10〜50オs程度である。一方、プロセッサの演算性能は、数百MFLOPSないし数GFLOPSである。テラフロップスマシンにおいても、演算性能とプロセッサ間データ転送性能のバランスが相似的に拡大できれば、現在使われているアルゴリズムや並列化手法をそのまま拡大するだけでテラフロップスに到達することができる。レーテンシは、データ転送に伴うプロトコル処理などを改善していくと、最終的には装置の規模に依存する。ペタフロップスを実現するシステムのプロセッサ台数は数千から10,000台規模となり、現在実用になっているシステムより1桁多い台数である。ハードウエア技術の進展を勘案しても装置規模が劇的に小さくなることは考えにくい。したがって、レーテンシの大きな削減は期待できず、演算性能とのバランスにおいては、現状より1〜2桁悪くなる。すなわち、ユーザにとって並列化が難しくなる方向にシステムバランスが移り、全体処理時間に占める実効的なデータ転送時間の割合を現状より1〜2桁小さくする並列化アルゴリズム/手法の開発が不可欠となる。
スループットについては、現在の代表的なシステムのシステムバランスは、富士通VP700の場合、プロセッサ単体性能が2.4GFLOPSに対してプロセッサ間データ転送スループット約1GB/s、CRAY T3Eが0.6GFLOPSに対して0.6GB/s、筑波大学のCP-PACSが0.3GFLOPSに対して0.3GB/sである。前述のように、テラフロップスマシンのプロセッサ単体性能はおよそ100GFLOPSであるから、現在の並列化アルゴリズム/プログラミング手法の継承を考えるなら、100GB/s程度のプロセッサ間データ転送スループットが必要になる。プロセッサ間結合ネットワークの動作周波数をプロセッサ動作周波数の約半分の1GHzと仮定すると、100GB/sを実現するには、数千から10,000台規模のプロセッサ間に100バイト程度のデータ線を張り巡らせる必要があり、非現実的である。プロセッサ間のデータ線幅は高々2〜8バイトと考えられるので、演算量に占めるデータ転送量の割合を、現状に比べ1〜2桁押さえる技術が必要となる。
以上をまとめると、ペタフロップスマシンを実用的なシステムとして実現するには、10,000台規模のプロセッサ並列を有効に使う並列処理技術のほか、演算性能とメモリ性能のギャップを埋める手段としてロジック・メモリ混載LSI技術の積極的活用、さらに、演算量に占めるデータ転送量の比率を現状より1〜2桁程度小さくする並列アルゴリズム/並列化プログラミング技術の開発が必要である。このうち、並列アルゴリズム/並列化プログラミング技術の開発が特に難しい課題と考えられ、並列処理ソフトウエア研究の強化がペタフロップスマシン実現にまず必要な施策と考えられる。
<参考文献>
(久門耕一委員)
日米でのペタフロップスマシンに対する大きな差は、実現に対するニーズの差である。米国では、核実験の計算機シミュレーションの必要性からテラフロップスマシンが実現された。米国としては、計算機上での核実験シミュレーションが可能になれば、費用削減、世論対策などの多くのメリットがある。また、そこで作られた技術を産業界へ転用することができるので、かつての軍事主導型の技術開発がうまく機能するものと考えられる。
一方、日本においては技術革新は主に産業界において進められてきたが、現時点ではバブル崩壊後の投資の冷え込みにより巨大システム構築のための余力がない。また、大規模システム開発は半導体産業ですら企業共同体でなければ開発が行えない状況になっており、また、多くの場合、日本企業同士の連合体を作りやすい風土はない。また、テラフロップスマシンをいくらで実現でき、結局いくら儲かるのかという費用対利益の構図がはっきりしないと企業連合が作成されることはないだろう。
ペタ(P)フロップス(flops)マシンの実現性の検討を行う際、コストの検討を避けて通ることはできない。もちろん、コスト以前の問題としてどのような応用に使用し、どのようなご利益があるのかを定義し、そのために必要な費用・構造を検討することが第一に必要ではあるが、ここではあえてそれを避け、現在作成可能と思われるアーキテクチャとその問題点について、実現面からの検討を行う。
(1)ペタフロップスマシンのハードウエア
単純に、単体性能に台数を掛けてペタフロップスを達成できるマシンを作ることでさえ現在使える技術では困難が多い。通常は、実性能を求める立場から、単体性能を極限まであげ、それを必要最小限に組み合わせると言う解がもっともらしいが、ここではそれに因われず、無闇と単体性能を向上させる方法と無闇に数で稼ぐ方法の2つを考えてみる。
(2) ペタフロップス・マシンの可能な構成法
従来は、計算機能をCPUに集中させ、大容量の記憶装置を周辺に配置する形でのシステムが多く作られてきた。並列計算機であっても、現段階で商用化されているものは、性能の高い単体ユニットをネットワークにより複数接続し並列化することで構成されている。このアーキテクチャのコスト的欠点とでも言うべきものは、CPUの稼働率は高いがメモリの稼働率はかなり低いということである。ここで言う稼働率は、あるビットやチップがアクセスされる率である。現実にある大規模な計算機システムにおいては、CPUよりもメモリやI/Oのコストがシステムコストの大半を占めている。特に、CPUとして汎用マイクロプロセッサを用いる場合はその傾向が大きい。すなわち、計算機システムの大半のコストはあまり利用されない部分にかかっていると言える。
このことを現在ありふれていそうなシステムを基準に検証してみる。
ここでは、ハイコストパフォーマンスなシステムとしてインテルPentium-Proを使用したシステムを考える。
| Pentium-PRO | 200M load or store /s 256K Cache |
|
| P6-Bus | 66MHz 8Byte |
|
| DRAM |
現在のPentium-PROは、200MHzのチップ内クロックで動作するSuper scalarプロセッサで、連続的に3命令ずつ実行する事ができる。このことから、プロセッサ自身は最大で600M命令/秒の実行が可能である。load/storeに限ってみても、毎クロック実行が可能であるから、200Mアクセス/秒のメモリアクセスが可能である。一方Pentium-PROが採用するP6バスは最大スループット約530MB/sである。これは、 8byte幅で66MHzのクロック速度により実現されている。この速度がPentium-PROと外部とのアクセス速度の上限となっている。また、現在使用されているメモリのアクセス速度は60ns程度のものであり、この段階で66MHzのバスクロックとの間に4倍程度の速度比が存在する。
これらから、CPUが最高の性能を発揮するためのバス速度を達成するためには、メモリを4wayインターリーブしなければならない。これを、64MbitDRAM(16Mbit×4)のチップで構成する場合には8byteバスにするため、16chip、4wayインターリーブのために4倍で合計64 chip、すなわち、512MBのメモリが搭載されることになる。
この単純な検討からもCPUのコストよりもメモリのコストが3.5倍も高価であることがわかる。それぞれの機能を実現するために必要なチップ面積を考えてもメモリが占めるチップ面積の方がはるかに大きいことがわかる。
次に、このすべてのメモリをCPUがアクセスするために必要な時間を算定する。512MB/ (520MB/s)からCPUが全メモリにアクセスするには少なくとも約1秒が必要である。すなわち、最高速度ですべてのメモリを順番にアクセスするようなプログラムでさえ、あるビットを平均1秒1回しかアクセスすることができない。メモリは大変に暇であるにも関わらずシステムコストの大きな部分が占められていることがわかる。システム性能に対するメモリの遅さを隠蔽するために用いられるキャッシュメモリを大きくすれば、実効性能は向上するがCPUのコストにそのまま影響してくる。
計算機システムがこのような構成を取るのは、
であるため、単一のCPUの性能を最大限に生かす周辺構造を持たせることが必要だからだと考えられる。
一方、Peta flopsマシンを考えると並列プログラミングの必要性は疑う余地はない。しかも、ノード数は少なく見ても10万程度は必要であるから、単体性能を向上して数を減らすというアプローチができるレベルではない。つまり、単体性能の無闇な向上はあきらめ、とにかく数を増やすことにより速度の向上を図ることが残された手段である。
さらに、単体nodeのメモリ価格を押えながら実質的なメモリ量を増やすために、図1の構造を取ると考えよう。
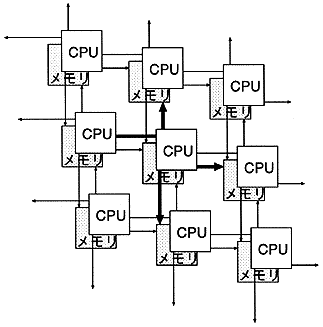
ここでは二次元メッシュ構造を示した。
この構造では各CPUはローカルにメモリを持つと同時に周囲のCPUのメモリへのアクセスも可能で、図1では、各メモリは計5ノードからのアクセスが可能である。この構造は、現実の物理現象が近接作用に基づくという前提に基づいている。実際には、三次元現象のシミュレーションへの適合性から三次元メッシュ構造が必要となる。現在の計算機システムではメモリのチップ面積とCPUのチップ面積の比率を見ると圧倒的にメモリの面積が大きい。しかし、上記の構造を取ってCPUの面積をメモリのチップ面積と互角にしても所詮はメモリのチップ面積が倍に増えるに過ぎない。
このようにして、1チップで1G bit RAMと1G flops CPUのペアを16個実装することが可能になるとして、このチップを65536チップ実装することで、計算上は1Pflopsが達成できる。アプリケーションをどのように実現するのかが最大の問題として残る。
実装上、このような構造で三次元メッシュを作製した場合、実世界の三次元構造をCPUのメッシュにマッピングするのが自然である。ここで、立方体の体積は辺の3乗、表面積は辺の2乗に比例するが、計算量は体積に比例し、通信量は表面積に比例すると考えられるため、辺を大きくするほど通信量が相対的に減少する。すなわち、通信路に対する負担が減るはずである。このことは、1つのnodeで大きな体積分の演算を行えば、辺の長さに逆比例して必要な通信速度が低下することを示している。
このチップ16個程度Multi Chip Module(MCM)により実装すれば、そのMCMを4096使用することで計65536CPUとなる。この段階まではチップ内と同じ通信速度が達成できると仮定する。熱設計の問題もあり、MCM間の結合は物理的に遠くせざるを得ない。MCMには256個の1G flopsプロセッサ、つまり計256G flopsが搭載できる。
このように構成されたMCMを通信路により結合するが、結合路として利用できそうなバンド幅は恐らく10G〜100G滷/sだろうと考えられる。これほど高速な通信は、シリアル通信で行うよりもパラレル通信を使う方が実現が容易であるが、当然線間のスキューの補償が必要である。
ここで問題となるのは、このような技術がアナログ的に行われるが、最近の傾向として大学などでもアナログハードウエアに対する比重が少なく、また企業内においてもアナログの技術者が欠けているということである。日本は、高速通信分野で世界のトップに位置しているが、このような高速通信のハードウエアは単品生産的に製造されるものが多い。しかし、ペタフロップスマシン実現のためには、このような技術をLSIあるいはMCMの中に搭載し大量に安定して製造する技術が求められている。すなわち、超高速アナログ技術を含んだLSI技術が必要である。同様に、LSIのチップ内の配線においても数百MHzを越える場合には、デジタルとはみなせないため、高速アナログ回路の技術が必要になる。残念ながら、最近の技術者でアナログ技術を習得している人はほとんどいない。シリコンバレーでも、論理設計だけでなく、Trレベルでの回路設計をこなして、Spiceシミュレーションにより自作のマクロの検証まで行う設計技術者の給与は、その雇主の社長の給料をも凌ぐと言われている。だから、日本では、技術者がいないのは仕方ないのかも知れない。このような技術に対するニーズは増えるが技術者が減っているのが現状であるから、大学教育の段階で何とか手を打っておく必要がある。
(3)マシンを何に使う
一般に、計算機の利用形態として以下の2つが考えられる。
高速電卓 すなわち技術者が考えたアイデアをシミュレーションにより確認するために計算機を用いる。各種のシミュレーションがこの目的である。
高機能電卓 計算機の膨大な探索能力を用いることで、最適解を求めるものである。
高機能電卓実現のためには高速電卓を用いたアイデア検証の積み重ねが必要であるため、高速→高機能の順に応用が開発されるものと考えられる。
高速電卓として使用する場合、何を入力として与え何が出力として得たいのかが重要なポイントとなる。マシンのメモリをすべて埋めるようなデータを入力できるわけはなく、出力も同様にできない。入力も、出力もある種の統計情報(例えば温度とか密度など)として与えることが現実的な解だろう。そういう意味では、入出力に高速性が求められるのは、中間結果の保存の場合だと考えられる。それなら、各ノードの結果を独立に保存すればよいので、大量のディスクをいかに結合・実装するかが焦点であり、並列ファイルシステムなどを考えなくてもよい。
今すぐにでもペタフロップスマシンを必要とする分野としては、材料分野でのデバイスシミュレーションが挙げられる。しかし、汎用高速計算機として使用することは困難で、アーキテクチャに適合できるシミュレーションアルゴリズムのみが計算の対象になる。(2)で述べた構造は、現実の三次元構造を各 CPU にマッピングすることを念頭においているため、現実世界のシミュレーションを行うにあたってアルゴリズムを考えることが可能だと思われる。
3.1.3.1でも述べたように、現状では産業界が独自にペタフロップスマシンを開発することは考えにくく、作るとすれば国が音頭を取る以外にないだろう。例えば、材料関係などの研究機関からの要望をまとめ、ニーズを実現するためのペタフロップスマシンを共同利用施設として実現することが必要だろう。その場合、ペタフロップスマシンそのものが課題となることはあり得ず、ペタフロップスマシンによって解かなければならない問題の方にこそ課題がある。
繰り返しになるが、このような巨大計算機システムのアーキテクチャはそれほどの自由度があるとも思えない。実現できるアーキテクチャ間での性能の差は高々数倍以内に留まるのではないだろうか。だとすれば、アーキテクチャの検討よりは、マシン実現により何が解決可能な問題なのかを分離し、それぞれの分野でどのように問題を定式化すれば狭い選択肢のアーキテクチャで並列処理が可能になるのかを検討することがマシン応用への最短経路だと考える。
(中島 浩委員)
本節ではPeta-Flops Machine(あるいはそれに相当する超大規模並列計算機)のアーキテクチャについて、メモリ機能を中心に議論する。また、超大規模並列計算機の研究開発に関する議論も行う。
まず以下の3点を議論の前提とする。
(1)超大容量メモリの必要性
想像を絶するようなパラダイム・シフトがない限り、Peta-FLOPS Machineにおいてもメモリは存在するものと予想される。また仮に「MIPS=MBの法則」が引続き成り立つとすると、その総容量はPeta-Byteのオーダでなければならない。
(2)演算/メモリ・スループットのバランス確保
Peta-FLOPSの性能を実際に得るためには、それに見合うだけのメモリ・スループットを確保する必要があるだろう。したがってPeta-FLOPS Machineは、同時にPeta-MOPS(Memory Operation Per Second)Machineでなければならない。
(3)von Neumann bottleneckの存在
Peta-FLOPS Machineが現状のようなMulti von Neumann Machineであるかは不明であるが、広義のvon Neumann bottleneckは解消できないものと予想される。すなわち、素子レベルのメモリ技術に革命的なブレイク・スルーがない限り、 Peta-Byteオーダのメモリと、それをアクセスするプロセッサ(あるいは演算器)との間に、物理的な隘路が生じるのは避けられないだろう。また、現状の技術の単純な延長を考えると、このbottleneckは相対的により細いものとなるのは明らかである。
上記の前提に基づけば、使い古された言葉ではあるが「von Neumann bottleneckの解消/緩和」が、Peta-FLOPS Machineのメモリ・アーキテクチャの鍵となると考えられる。すなわち、現状ではこのbottleneckをアドレスやデータが通過しているが、これをより通過しやすい形に変質させることを考える。
以下、「bottleneck通過物の変質」の候補として、プロセッサからメモリへの機能移動を取り上げて議論する。
メモリがプログラムから可視であることは当然であるが、メモリ・システムのすべての要素が可視であるとは限らない。その代表例は現状のキャッシュであり、その挙動をプログラムが制御するのは極めて困難である。
例えばキャッシュが前提としている時間的/空間的局所性が成り立たないようなプログラムでは、不要なキャッシングやキャッシュの汚染が生じるが、これを避けるのは困難である場合が多い。また、共有メモリ型の並列計算機で行われるキャッシュの一貫性管理は、局所性の前提に加えて共有データのアクセス特性に関する前提があるため、キャッシュが無効あるいは有害となる可能性はさらに高くなる。
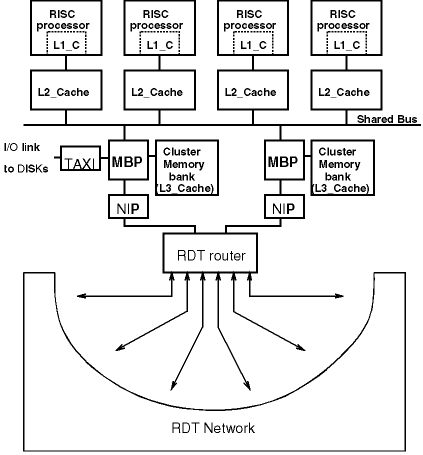
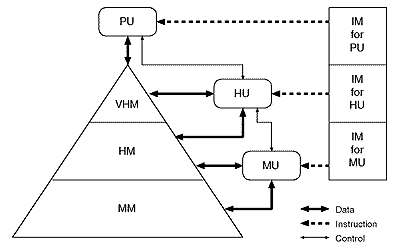
このような問題を解決する方法として、キャッシュをはじめとするメモリ・システムの要素を可視化して、何らかの制御を可能とするようなアーキテクチャがいくつか提案されている。例えばJUMP-1[1](図1)では、さまざまな一貫性管理や高度なメモリ機能を用意し、ソフトウエアが適切なものを選択できるようにしている。またソフトウエアによる一貫性管理に関するさまざまな研究も行われており[2]、我々の研究でも適切なハードウエア・サポートがあればハードウエアのみによる一貫性管理よりもよい性能が得られることを示している[3]。
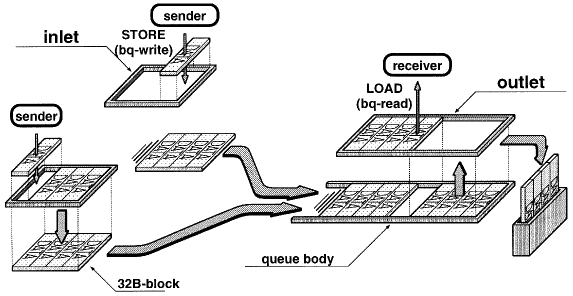
この他、アクセスするデータの種類によって、時間的局所性を重視した通常のキャッシュと、空間的局所性や(データではなく)操作の時間的局所性を利用するバッファ的なキャッシュとを併用する試みもあり、例えば我々が提案しているVirtual濂ueueもその一つである(図2)[4]。またHewlett Packard社のPA-RISCの一部に採用されているAssist Cacheも、ある意味ではアクセス特性によってキャッシュを使い分ける方式である。
これらの、キャッシュをはじめとするメモリ・システムの要素の可視化における重要な問題点として、ソフトウエアとのインタフェースの設定があげられる。単純な方法としてはメモリ・システムを制御するための命令の追加があり、すでにプリフェッチなどを命令セットに加えているプロセッサは多い。別の方法としては、JUMP-1のようにアドレスの一部を制御に使うというものもある。いずれにせよ、均一であることが大きな特徴であったメモリ・システムを非均一にし、しかも相当な期間にわたって安定したインタフェースを設定するのは、必ずしも容易ではない。したがって、可視であるような要素を含む非均一なメモリ・システムの統一的ビューを設定し、ソフトウエアが安定的に利用できるようにすることが重要な課題である。
前項の可視化は、あくまでプロセッサが制御の主体となるものであるが、制御をメモリに移管してプログラムの実行をメモリが分担する試みもなされている。例えば、JUMP-1にも採用されている松本らのMBP[5]や、KuskinとGuptaらのFLASH[6]はその例であり、メモリに密接に結合されたプロセッサにより一定のメモリ機能をプログラマブルに実現するものである。
さらに先鋭的なアプローチとしては、牧らによるUPCHMS[7]がある(図3)。これはメモリ階層のそれぞれに独立して動作するプロセッサを配し、階層間のデータ転送を全てプログラム制御しようというアーキテクチャである。この方式には、階層間の制御情報を適切なタイミングで受け渡す方法や、階層ごとのプログラムをいかに生成するなど、さまざまな問題点があるが、メモリ・アクセスの新たなパラダイムを見い出す試みの一つとして興味が持たれるアプローチである。
これらの方法にはいずれも、適切なタイミングでメモリをアクセスするための情報が、アドレスの列よりも十分に小さくできる、という共通の基盤があり、この基盤から新たなメモリ・アーキテクチャを生み出せる可能性がある。
前項の制御/機能のメモリへの移管をさらに押し進めると、以下のような新たなアーキテクチャを想起することができる。
このようなモデルを仮にCode Flow Modelと名付けると、ある意味でData Flow Modelの双対として考えることができる。もちろん、上記のようなモデルを直接ハードウエアにマッピングすることは(Data Flow以上に)困難であり、実現のためには何らかの変換が必要となる。例えば、以下のような変形が考えられる。
このモデルを仮にPC Flow Modelと名付けると、第0近似としては以下のようなものが考えられる。
このようなアーキテクチャがはたして現実的でかつ有効であるかには、もちろん疑問点が多々あるが、広義のvon Neumann bottleneckを通過するものを大きく変質させていることは明らかである。また、このような根源的なパラダイム・シフトを行うか否かに関わらず、並列計算を構成する要素がどのような時間的/空間的な分布をしているべきかを、原点から見直す必要があると考える。
Peta-FLOPS Machineのような超大規模の並列計算機に関する研究開発を行う上で、最も問題になるのは研究プラットフォームである。特にソフトウエアに関する研究開発には、ある程度大規模なプラットフォームが必要であるが、現状ではそのような環境を有する研究者はごく限られている。もちろん大規模な並列計算機を有する大学や公的研究機関は少なくないが、それらのほとんどは実際に大規模計算を行うユーザのためのものであり、コンパイラやOSの研究者のプラットフォームとはなり得ない。
このようなプラットフォームの存在が研究開発を飛躍的に進めることの好例は、数年前に富士通が行ったAP-1000の無償使用と無償貸与であり、AP-1000を利用して非常に多数の研究論文が生み出されたことは記憶に新しい。このようなプラットフォーム整備を一民間企業に頼るべきではなく、本来は公的組織が主導的に進めることが強く望まれる。
またハードウエアのみならず、研究開発用のソフトウエア・プラットフォーム、例えばシミュレータ、コンパイラ・ツール、仮想並列マシンなどの整備も必要である。このようなソフトウエア資産をIPAのような枠組を利用して育成することも、重要な課題として検討すべきである。
<参考文献>